Prompt engineering had a good run. Somewhere around 2023-2024, it felt like the most important skill you could learn. Write the right magic words, get better outputs. Makes sense on the surface.
The problem? That framing is fundamentally broken for how AI systems actually work now.
Context engineering is the thing people who build serious AI systems are quietly obsessing over. Not “how do I phrase this better” but “what information does the model need, in what form, delivered when, to actually produce something useful.” That shift sounds small. It isn’t.
What Context Engineering Actually Is (And Why It’s Not Just a Fancy Name for Prompting)
Here’s the honest distinction: prompt engineering is about the words you type. Context engineering is about the entire information environment the model operates in.
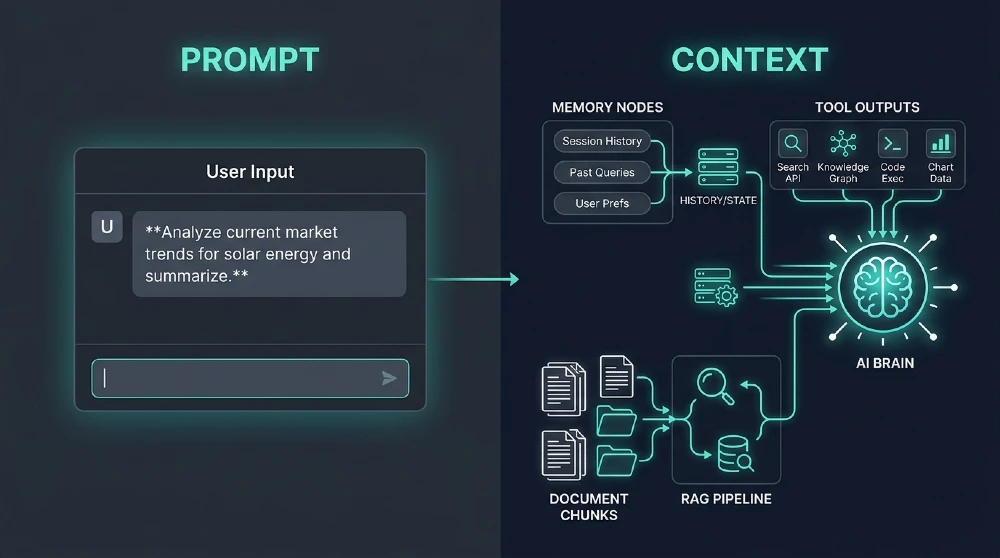
When you write a prompt, you’re crafting one input. When you do context engineering, you’re designing a system — what goes into the context window, in what order, with what structure, from what sources, refreshed at what intervals. You’re thinking about retrieval pipelines, memory architecture, tool outputs, conversation history compression, system instructions layering, and what to deliberately leave out.
Andrej Karpathy, one of the original architects behind GPT-4 at OpenAI, put it plainly on X in mid-2025: context engineering is “the delicate art of filling the context window with just the right information.” That framing stuck because it’s accurate. The context window isn’t a text box you fill randomly it’s a precision instrument.
Most people building on top of models like Claude 3.5 Sonnet, GPT-4o, or Gemini 1.5 Pro are still thinking at the prompt level. That’s why their agents hallucinate, loop, forget things three steps in, or produce outputs that look good in demos and break in production.
The ones getting consistent, reliable results? They’ve moved to context engineering. Full stop.
Why Prompt Engineering Stops Working at Scale
You can prompt your way to decent single-turn outputs. Ask a well-phrased question, get a solid answer. Fine.
The moment you need the model to do multi-step reasoning, maintain state across a long workflow, use tools correctly, or operate inside an agentic loop prompt cleverness runs out fast.
Here’s what actually happens. Say you’re building an AI research agent. You write a beautiful system prompt. Detailed, specific, exactly right. It works great in your first five tests. Then you give it a real task pull data from three sources, reconcile conflicts, write a structured report. By step four, it’s lost track of constraints you set in step one. By step seven, it’s contradicting itself. By step ten, it’s confidently fabricating citations.
That’s not a prompting problem. That’s a context problem. The model didn’t “forget” your instructions those instructions got diluted, compressed, or buried under the accumulated weight of tool outputs, retrieved chunks, and conversation history that you didn’t architect carefully.
I’ve seen this exact failure pattern across dozens of agent builds. The fix is never “write a better prompt.” The fix is always structural how information enters and persists in the context window.
The Six Layers of Context Engineering
Think of context as having distinct layers, each one requiring deliberate design choices.
System instructions sit at the base. Not just role-setting (“you are a helpful assistant”) but precise behavioral constraints, output format specifications, escalation rules, and explicit boundaries. The difference between a system prompt that degrades under pressure and one that holds? Specificity and structure not length.
Retrieved context is what your retrieval-augmented generation (RAG) pipeline pulls in. Most people do naive RAG: chunk documents, embed them, retrieve top-k by cosine similarity, dump them in. That works poorly. Good context engineering means thinking about chunk size relative to your task, re-ranking retrieved results, filtering by recency or authority, and critically deciding how much retrieved content the model actually needs versus what’s noise.
Tool outputs are where agents fall apart most often. When a tool returns a 4,000-word API response and you shove the whole thing into context, you’ve just buried your actual task instructions under irrelevant data. Context engineering means processing tool outputs before they enter the window — summarize, filter, structure, extract only what’s needed.
Conversation history is memory, and memory is complicated. Long conversations accumulate fast. Naive approaches keep everything. Smart context engineering compresses, summarizes, or selectively retains only what’s relevant to the current step. Tools like LangChain’s ConversationSummaryMemory or LlamaIndex’s chat engines do some of this but you still need to make the architectural decisions about what matters.
Working state is the structured data your agent maintains across steps task progress, decisions made, variables tracked. Most beginner agent builds treat this as ad-hoc. Experienced builders maintain explicit state objects that get serialized and injected into context at each step, so the model always knows exactly where it is in a workflow.
Negative space what you deliberately exclude might be the most underrated layer. Every token you put in context costs attention. Irrelevant content doesn’t just waste tokens; it actively degrades reasoning. The discipline of leaving things out is as important as choosing what to include.
The Real-World Difference This Makes
Let me give you a concrete example from something I tested about eight months ago.
I was building a due diligence assistant for startup investment research. The task: given a company name, pull together a structured analysis covering team background, market size, competitive landscape, recent funding, and risk factors.
First version: pure prompt engineering. Long, detailed system prompt telling the model exactly what to research and how to structure the output. Used web search tools, scraped LinkedIn, pulled Crunchbase data.
Results were inconsistent. Sometimes great. Often the model would get distracted by irrelevant details from search results, miss key competitive players, or confidently state funding amounts that were outdated or wrong.
Second version: context engineering. Same tools, completely different architecture. Tool outputs got processed through a summarization step before hitting the main context. Each research category got its own context slot with clear labels. Retrieved chunks were re-ranked by relevance to the specific section being written. State tracking made sure the model knew which parts of the analysis it had completed.
Same underlying model. The difference in output quality was not subtle it was the difference between something I’d trust to share and something I’d have to rewrite entirely.
That’s context engineering in practice.
How Context Engineering Connects to Agentic AI
This is where it gets important for anyone building or using autonomous AI agents. Single-turn interactions are almost irrelevant at this point for serious applications. The action is in multi-step, tool-using, memory-having agent systems.
And agent reliability lives or dies on context quality.
The reason most agent demos fail in production isn’t model capability today’s frontier models are genuinely impressive. The reason is context collapse. The agent loses track of its goal. It gets confused by contradictory information in its window. It acts on stale data. It repeats steps it already completed because it can’t correctly read its own state.
Every one of these is a context architecture failure.
If you’re working with frameworks like Agent Zero or similar agentic systems, you’ll notice that the most impactful configuration decisions aren’t about which model you pick they’re about how the system manages context across agent steps. Memory persistence, tool output handling, sub-agent communication all of it is context engineering under the hood.
Practical Context Engineering: Where to Start
If you’ve been doing prompt engineering and want to upgrade your approach, here’s where to actually begin.
Audit what’s in your context window. Most people have never looked carefully at what’s actually sitting in the context window during execution. Log it. Read it. You’ll probably find a ton of noise redundant instructions, massive tool outputs, irrelevant history. That’s your first optimization target.
Structure before size. A 500-token, well-structured context chunk outperforms a 3,000-token raw dump almost every time. Use XML tags, clear section headers, explicit labels. Models like Claude respond significantly better to structured context than unstructured walls of text. Anthropic’s own documentation confirms this structured inputs produce more reliable, format-consistent outputs.
Think about ordering. What comes first in context matters. Models give disproportionate weight to content at the beginning and end of the context window (this is called the “lost in the middle” effect, documented in a 2023 Stanford study). Put your most critical constraints and current task at the top. Don’t bury the actual instruction under 2,000 tokens of background.
Implement progressive summarization. Long conversations and long agent runs need a compression strategy. At defined checkpoints, summarize what’s happened so far into a compact state representation. Keep that summary, drop the raw history. This alone can dramatically improve agent coherence on long tasks.
Design your retrieval pipeline seriously. If you’re using RAG and most production systems do don’t use default chunk sizes and top-k settings. Experiment. For dense technical content, smaller chunks (256-512 tokens) with higher overlap often work better. For narrative content, larger chunks preserve more coherence. Re-ranking retrieved results using a cross-encoder model (Cohere Rerank, for example) reliably improves relevance over pure vector similarity.
The Tools People Are Actually Using
Context engineering isn’t purely theoretical there’s a growing toolkit around it.
LlamaIndex has become the go-to for sophisticated retrieval and context management. Their query engine abstractions let you build multi-stage retrieval pipelines, combine vector search with structured queries, and implement context compression all without reinventing every wheel.
LangChain’s LCEL (LangChain Expression Language) gives you compositional control over how context flows through chains. Once you understand it, you can build pipelines that process, filter, and structure context at each step rather than passing raw outputs through.
mem0 is specifically designed for persistent memory in AI applications giving agents the ability to recall relevant information across sessions without bloating the context window with everything from every previous interaction.
DSPy from Stanford takes a different angle: instead of manually engineering prompts and context, you define what you want and let it optimize the instructions and context structure through a compilation process. It’s experimental but genuinely interesting for teams doing serious agent development.
For the model side, if you’re working on something that needs deep context engineering, Claude 3.5 Sonnet and Gemini 1.5 Pro both have large context windows (200K and 1M tokens respectively) but bigger window doesn’t mean better results if you fill it badly. The discipline still applies.
What Context Engineering Means for Your Career
If you’ve been building prompt engineering skills, good news: they transfer. Bad news: they’re not enough anymore.
The agentic AI job market is asking for people who understand how to build reliable AI systems, not just people who can write clever instructions. Job descriptions in 2026 that used to say “prompt engineering experience” are now saying things like “RAG pipeline design,” “agent memory architecture,” “context window optimization.” Same underlying domain, higher technical bar.
What makes someone good at context engineering? Honestly, it’s less “AI knowledge” and more systems thinking. You’re designing information flows. You’re thinking about what a model needs to know, when it needs to know it, and what happens when context gets polluted or corrupted. Those are software architecture instincts applied to a new domain.
People coming from data engineering, backend development, or information architecture backgrounds pick this up fast. The model is almost incidental it’s the plumbing around it that separates good from bad.
Common Mistakes (And How They Play Out)
Treating context as unlimited. Even with large context windows, attention degrades. Filling a 200K token window with semi-relevant content and expecting peak performance is a mistake. Quality over quantity, always.
Static system prompts for dynamic tasks. One fixed system prompt for an agent that does wildly different things at different steps is lazy architecture. Different task phases often need different instruction sets injected into context.
No state management. Agents without explicit state tracking rely on the model to “remember” what it’s done by reading its own output history. That fails unpredictably. Maintain structured state. Serialize it. Inject it explicitly.
Ignoring tool output size. I see this constantly. A search tool returns ten results with full text. Developer throws all of it into context. Model gets confused, picks irrelevant information, and produces a bloated output. Process tool outputs. Extract what matters. Summarize the rest.
Over-indexing on the model. Switching from GPT-4o to Claude to Gemini without fixing your context architecture is rearranging deck chairs. If your context pipeline is broken, a better model makes it fail more confidently. Fix the architecture first, then optimize the model choice.
The Advanced Stuff: Where Context Engineering Gets Interesting
Once you’ve got the basics solid, there are some genuinely sophisticated patterns worth exploring.
Hierarchical context management running a high-level orchestrator agent with a strategic context, while sub-agents operate with task-specific, narrow contexts. The orchestrator manages overall state; sub-agents stay focused. This is how the best multi-agent systems avoid context collapse at scale. If you’re working with systems likeAgent Zero via Docker, this architecture becomes relevant quickly.
Dynamic instruction injection rather than a static system prompt, building infrastructure that assembles system instructions dynamically based on the current task phase, user context, and available tools. More complex to build, dramatically more reliable in production.
Context distillation running a model pass specifically to compress and restructure context before it hits your main model. You’re spending tokens to save tokens, but if it improves reasoning quality, the trade is usually worth it.
Episodic memory with relevance scoring instead of storing all history or summarizing everything, maintaining a vector store of “episodes” (key moments, decisions, facts) and retrieving only the most relevant ones for the current step. mem0 does a version of this. Building it yourself gives you more control.
These aren’t theoretical. They’re patterns that teams at Cognition (Devin), Adept, and various enterprise AI shops are running in production right now.
Where Prompt Engineering Still Matters
Not going to pretend prompt engineering is useless it’s not. For single-turn interactions, it’s still the primary lever. For zero-shot tasks where you can’t build a full pipeline, prompt craft matters. For jailbreak resistance and output format control on simple tasks, the wording of your instructions genuinely matters.
The advanced prompt engineering techniques you’ve learned chain of thought, few-shot examples, role specification, output format instructions these become ingredients in your context engineering approach, not replacements for it. They’re the sentence-level decisions inside a document-level architecture.
Think of it this way: prompt engineering is typography. Context engineering is layout, hierarchy, and information architecture. You need both. But one operates at a fundamentally higher level than the other.
Real Talk: How Hard Is This to Learn?
Harder than prompt engineering. Easier than full-stack development.
The conceptual shift takes maybe a week of really engaging with it reading about RAG pipelines, playing with LlamaIndex or LangChain, building a simple agent and watching where it breaks. The moment it clicks that the model isn’t the hard part, the context architecture is that’s when you start making real progress.
After that, it’s reps. Build systems, watch them fail, figure out why the context broke, fix it, repeat. I’d say it took me around three months of regular building to get to a point where I could design a context architecture upfront and have it mostly work, rather than debugging backwards from broken outputs.
The people who learn it fastest are the ones who treat the context window as a first-class engineering concern from day one — not an afterthought they optimize once the “real” code is working.
What to Do Next (Actual Steps, Not Vague Advice)
Pick one agent or AI system you’ve built or used that produces inconsistent results. Don’t start fresh diagnose something broken.
Log your full context window during a failing run. Read it carefully. Identify the three biggest sources of noise or irrelevant content. Remove or compress them. Test again.
If you haven’t built a RAG pipeline yet, build a minimal one with LlamaIndex this week not because RAG is magic, but because the exercise of thinking about chunking, retrieval, and context injection makes context engineering concrete in a way that reading about it doesn’t.
Then look at the Agent Zero prompts guide for practical examples of how system instructions and context structure interact in a real agent system.
The skill gap between people who think about prompts and people who think about context is widening fast. The good news: most people still haven’t made the shift. You’ve got a real window to get ahead of it.
The AI Journal covers applied AI systems, agent development, and practical ML topics for builders. Browse the full site for more.


