
| Generative AI models — whether for text, images, or code — produce outputs that are only as good as the data they are trained on. Dirty, incomplete, biased, or inconsistent training data leads to hallucinations, wrong outputs, and unreliable AI systems. Fixing data quality is not a one-time cleanup. It is an ongoing process of validation, labeling, deduplication, and governance that must happen before, during, and after model training. |
Why Your Generative AI Keeps Getting Things Wrong
The most common reason a generative AI model produces wrong, biased, or confusing output is not the model itself. It is the data used to train it. This is true whether you are building a large language model from scratch, fine-tuning an existing one like GPT or LLaMA, or running a retrieval-augmented generation (RAG) system for customer support.
Generative AI learns by finding patterns in data. If the data has wrong patterns — duplicate records, missing values, inconsistent labels, outdated facts, or biased examples — the model learns those wrong patterns and repeats them at scale.
So the real question is not “how do we build a better model?” The question is: “how do we give the model data that is worth learning from?” That is what this article covers, step by step, with specific methods and real-world consequences at each point.
What ‘Data Quality’ Actually Means in the Context of Generative AI
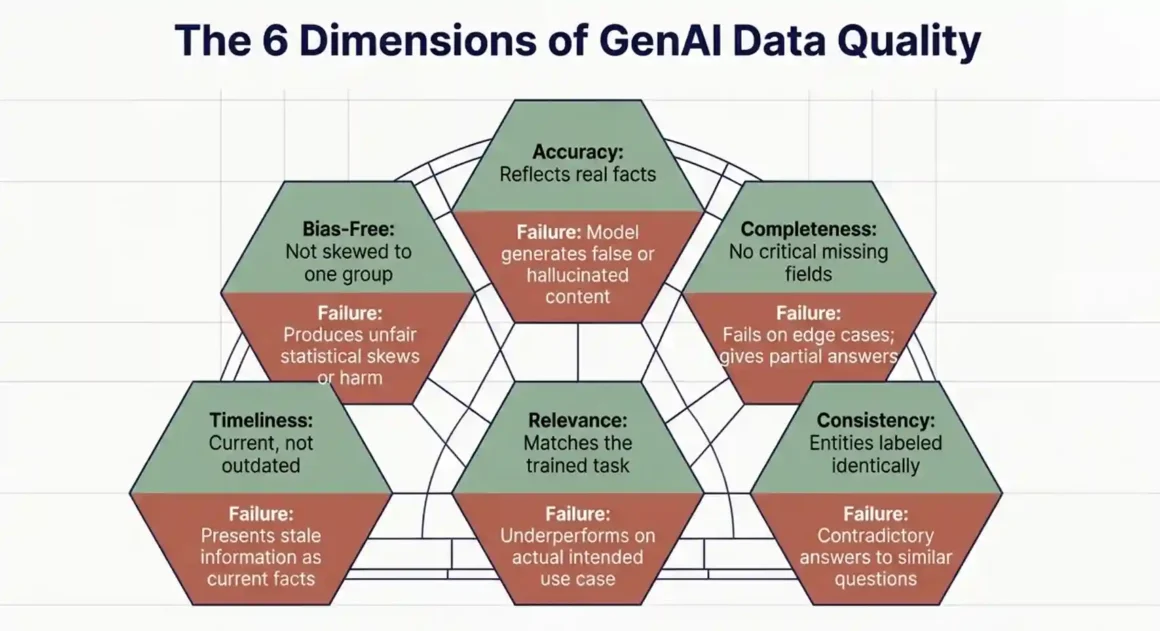
Data quality is not just about fixing typos. In generative AI, it refers to six specific properties that the training data must have. Each one affects a different part of how the model learns and behaves.
| Quality Dimension | What It Means | What Breaks When It Is Missing |
| Accuracy | Data reflects real, correct facts | Model generates false or hallucinated content |
| Completeness | No critical fields or values are missing | Model fails to handle edge cases; gives partial answers |
| Consistency | Same entities are labeled the same way everywhere | Model gives contradictory answers to similar questions |
| Relevance | Data matches the task the model is trained for | Model underperforms on the actual use case |
| Timeliness | Data is current, not outdated | Model gives stale information as if it is current |
| Bias-free | Data is not skewed toward one group or viewpoint | Model produces biased, unfair, or harmful outputs |
Most teams that build or fine-tune AI models focus heavily on model architecture and completely ignore three or four of these dimensions. The result is a model that technically runs but produces outputs that cannot be trusted. Accuracy without completeness gives overconfident answers. Consistency without relevance wastes compute on data that does not match the problem.
How Bad Data Directly Damages a Generative AI Model
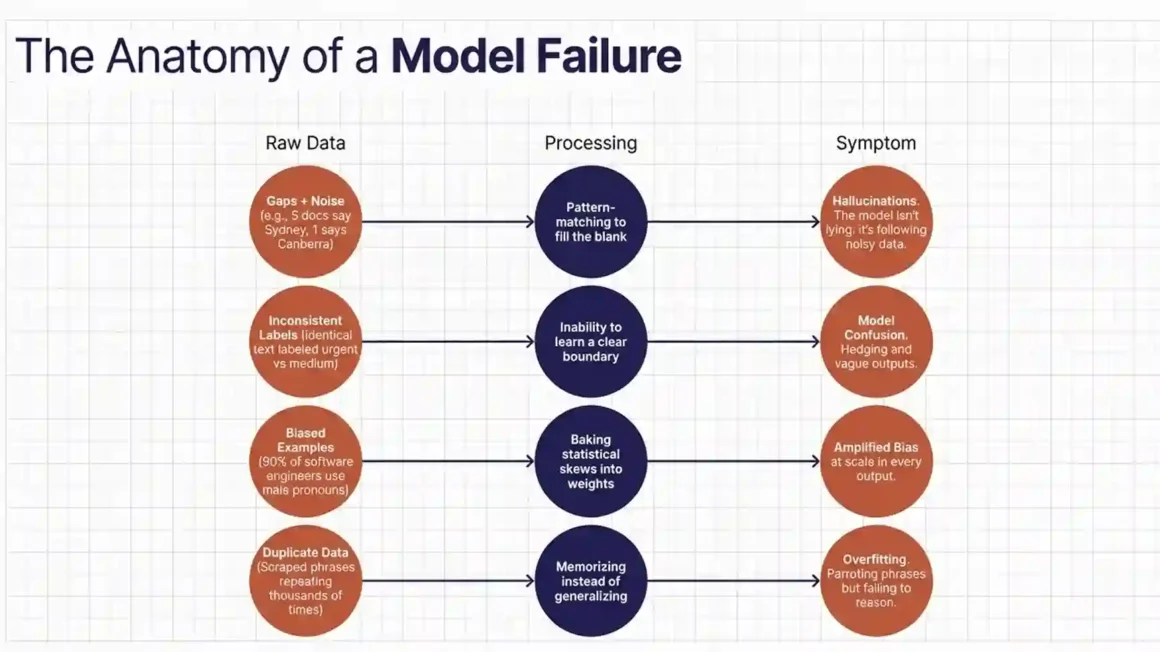
Before going into solutions, it helps to understand exactly what happens inside a model when the training data is poor. This is not theoretical. These are measurable effects.
Problem 1: Hallucinations Come From Data Gaps and Noise
Hallucination — when a generative AI confidently states something false — is usually blamed on the model. But in most cases, the root cause is a data problem.
When a model is trained on data with gaps (topics that appear rarely or are described inconsistently), it learns to fill those gaps by pattern-matching similar content. If the data says ‘the capital of Australia is Sydney’ in five documents and ‘the capital is Canberra’ in one, the model learns to say Sydney. It is not lying. It is following the data.
The fix here is not a model fix. It is a data fix. Specifically: deduplication to remove repeated wrong entries, and source quality scoring to weight authoritative sources more heavily during training.
Problem 2: Inconsistent Labels Make the Model Confused
In fine-tuning and supervised training, you give the model input-output pairs. If the same input is labeled differently across your dataset — for example, a customer complaint is labeled ‘urgent’ in one place and ‘medium’ in another for identical text — the model cannot learn a clear boundary. It starts hedging, giving vague outputs, or randomly switching between classes.
This is one of the most common quality problems in enterprise AI projects. It happens because different human annotators label data at different times, without clear guidelines. The model does not know which label is correct. It just averages the uncertainty, and the output becomes unreliable.
Problem 3: Biased Training Data Produces Biased Outputs — At Scale
If 90% of your training data on ‘software engineers’ uses male pronouns, the model learns that software engineers are male. When asked to write a job description or a story, it will default to that pattern. This is not an opinion the model forms. It is a statistical pattern it learned from skewed data.
The dangerous part is scale. One biased human document has limited reach. A biased AI model used by thousands of people repeats that bias in every single output. Fixing bias in training data is not just an ethical task. It is a product quality task.
Problem 4: Duplicate Data Overfits the Model
If a specific document, sentence, or phrase appears thousands of times in your training corpus, the model memorizes it rather than learning from it. This is called overfitting. It leads to a model that can recite that specific content perfectly but cannot generalize or apply the concept to new situations.
In large language model training, duplicate web pages and scraped content are a major source of this. Models trained on heavily duplicated internet data tend to ‘parrot’ common phrases rather than reason through new problems. Deduplication — at the document level and at the n-gram level — is one of the highest-impact data quality steps.
Explore AI ethics business rollouts. Agent Zero governance frameworks ensure enterprise compliance from day one. Responsible AI scales production safely with built-in ethical guardrails!
The Real Cost of Ignoring Data Quality: What Happens in Production
Here is what bad data quality actually looks like when an AI system goes live. These are not hypothetical scenarios.
| Real Scenario: Customer Support AIA retail company fine-tunes a language model on three years of customer support chat logs. The logs contain: resolved complaints with no resolution marked, agents who copy-paste the same response 400 times, outdated product information, and customer names embedded in responses. The resulting model gives repetitive answers, cites discontinued products, and occasionally inserts placeholder names like ‘[CUSTOMER_NAME]’ into responses. The fix required going back to data — not rebuilding the model. |
The cost of fixing data quality after model training is roughly 5 to 10 times more expensive than fixing it before training. You have to retrain or fine-tune the model again, which means compute costs, time, and in many cases, going back to collect and re-label data from scratch.
Teams that invest in data quality pipelines before training consistently report fewer retraining cycles, higher model accuracy on benchmark tests, and better user satisfaction scores after deployment. The upfront work on data quality is not extra work. It replaces the reactive work of debugging a model that cannot be trusted.
How to Fix Data Quality for Generative AI: A Step-by-Step Process

This is not a generic list of tips. These are the specific steps, in order, with tools and decisions at each stage.
Step 1: Audit Your Raw Data Before Touching the Model
Before any training or fine-tuning, run a full data audit. This means analyzing the dataset for each of the six quality dimensions listed earlier. You are looking for:
- What percentage of records have missing values in key fields?
- What is the duplication rate at the document level and sentence level?
- Are labels or categories applied consistently across annotators?
- What is the date range of the data — is it still relevant?
- Does the data distribution match the real-world distribution of your use case?
Use Python with pandas and Great Expectations (an open-source data validation framework) to run these checks programmatically. Great Expectations lets you write rules like ‘the label column must contain only these five values’ and ‘no more than 5% of rows can have null values’ — and it flags violations automatically.
Do NOT skip this step because the dataset ‘looks fine.’ Most quality problems in AI training data are invisible to a human reviewer doing spot checks. They only appear when you run statistical analysis across the full dataset.
Step 2: Deduplicate — More Aggressively Than You Think
Deduplication in AI training data goes beyond removing identical records. You need to remove near-duplicates — documents that say the same thing in slightly different words. This is called semantic or fuzzy deduplication.
The tool used in most large-scale LLM training pipelines is MinHash LSH (Locality-Sensitive Hashing). It works by converting each document into a compact signature and then comparing signatures to find documents that are highly similar. You can implement this using the datasketch Python library.
| What to do vs. what NOT to do in deduplicationDO: Run deduplication at both the document level (remove identical pages) and the n-gram level (detect reused passages across different pages). DO NOT: Remove all repetition blindly. Some concepts are legitimately repeated in training data and should be represented multiple times. Set a similarity threshold — documents above 80% similarity are candidates for deduplication, not guaranteed duplicates. Review a sample before deleting. |
Step 3: Standardize and Normalize Before Labeling
Inconsistency in how the same entity is written creates silent quality problems. ‘New York,’ ‘new york,’ ‘NY,’ and ‘New York City’ might all refer to the same city, but a model trained on inconsistently written data treats them as different entities.
Before labeling or fine-tuning, run normalization on text data: lowercase everything where casing is not semantically meaningful, standardize date formats, resolve entity aliases (use a single canonical form for each named entity), and strip formatting artifacts like HTML tags, extra whitespace, or encoding errors (common in web-scraped data).
For structured data used in RAG systems, enforce a strict schema. Every document chunk going into the vector database should have the same metadata fields — source, date, category, version — filled in completely. A chunk with a missing date or unknown source cannot be trusted when the retrieval system uses that metadata for filtering.
Step 4: Build Clear Annotation Guidelines Before Human Labeling
If any part of your training pipeline involves humans labeling data — whether for classification, preference ranking in RLHF (Reinforcement Learning from Human Feedback), or named entity recognition — the quality of those labels depends entirely on how specific your guidelines are.
Vague guidelines like ‘label this as positive or negative sentiment’ produce inconsistent labels. Specific guidelines like ‘label as positive if the customer expresses satisfaction with the resolution, regardless of the initial complaint’ produce consistent labels.
Before sending data to annotators, create an annotation guide that includes:
- A precise definition of each label or category
- At least 10 example data points for each label, including edge cases
- A list of common mistakes and how to avoid them
- A decision tree for ambiguous cases
Then run an inter-annotator agreement check on a sample of data labeled by multiple annotators. Cohen’s Kappa is the standard metric — a score above 0.7 is generally acceptable for NLP tasks. If your Kappa is below 0.6, the guidelines are not clear enough. Fix the guidelines, re-label the sample, and check again before labeling the full dataset.
Explore Grok AI free limits plans and alternatives. xAI’s Grok-4.1 free tier caps at 50 queries/day, Pro $20/month unlimited. Agent Zero + DeepSeek R1 offers superior cost/performance—scale AI without limits!
Step 5: Score and Filter Data by Quality Before Training
Not all data in a dataset should be treated equally. High-quality, authoritative sources should contribute more to what the model learns than low-quality, noisy sources. Quality scoring lets you assign weights or filter thresholds to different data sources.
One practical way to do this: create a small, manually curated ‘gold dataset’ of high-quality examples for your task. Then use a classifier or a simple rule-based scoring system to score your larger dataset against the gold dataset. Documents with very low similarity to the gold dataset get filtered out or downweighted.
This is the approach used in training data curation for models like Mistral and LLaMA. The full internet is scraped, but the training corpus is a carefully filtered subset where low-quality content — spam, non-linguistic content, near-duplicate content — is removed.
Step 6: Detect and Reduce Bias in the Data Distribution
Bias detection in training data is a concrete, measurable process — not just a philosophical exercise. Here is how to do it:
First, identify the sensitive attributes in your data: gender, race, geography, age, language. Then measure the distribution of these attributes across your dataset. If 80% of your training examples about ‘CEOs’ feature one demographic group, your data is biased toward that group.
Second, apply targeted resampling or reweighting. Oversampling underrepresented groups means including more examples of those groups. Undersampling overrepresented groups means removing some examples of the dominant group. The goal is a distribution that reflects the real world or your intended use case — not the historical biases baked into available data.
Do NOT try to fix bias only at the model output stage (for example, with post-processing filters). Filtering outputs is a band-aid. The bias is still in the model weights. The only reliable fix is in the training data itself.
Explore open-source RAG frameworks guide. LlamaIndex/Haystack boost Agent Zero accuracy 90%. Docker-ready context-aware agents without proprietary vendor lock-in!
Data Quality in RAG Systems: A Different Set of Problems

Retrieval-Augmented Generation (RAG) is now one of the most common ways to use generative AI in enterprise applications. Instead of relying only on what was in the training data, RAG systems retrieve relevant documents from a knowledge base at query time and include them in the prompt. The model then generates a response based on both its training and the retrieved documents.
In RAG systems, data quality problems show up differently than in training data problems. The model itself might be perfectly trained. But if the retrieved documents are low quality, the output is still wrong.
| RAG Data Quality Problem | Specific Cause | Fix |
| Wrong documents retrieved | Chunk boundaries cut context incorrectly | Use semantic chunking, not fixed-size splits |
| Outdated information cited | Knowledge base not updated regularly | Add ingestion timestamps and TTL policies |
| Conflicting documents retrieved | Multiple sources contradict each other | Add source authority scores for ranking |
| Model ignores retrieved content | Retrieved chunk is too long or irrelevant | Filter by relevance score before injecting into prompt |
| Missing metadata causes retrieval failure | Metadata fields incomplete | Enforce schema validation at ingestion time |
The Chunking Problem in RAG Is a Data Quality Problem
One of the most overlooked data quality issues in RAG systems is how documents are split into chunks before being embedded and stored in a vector database. If you split a document every 500 tokens regardless of content structure, you will inevitably cut sentences in half, separate a question from its answer, or break a table across two chunks.
When those broken chunks are retrieved, the model gets incomplete context and either ignores the chunk or misinterprets it. The output looks like a model hallucination, but the actual cause is a data quality problem — specifically, a chunking strategy that ignored document structure.
The fix is to use structure-aware chunking. Split documents at natural boundaries: paragraph breaks, section headers, list items. For documents with tables or code blocks, treat each table or code block as its own chunk. Libraries like LlamaIndex and LangChain both support recursive text splitting with structure-aware separators. Use those instead of naive fixed-size splitting.
Ongoing Data Quality: What to Do After the Model Is Deployed
Data quality is not a one-time task before training. The data landscape changes after deployment. New data comes in, the world changes, and user behavior generates signals about where the model is failing.
Monitor Output Quality to Find Data Problems
After deployment, track model outputs systematically. The most useful metrics are:
- Hallucination rate: how often does the model state something that contradicts your knowledge base or verified facts? This can be measured with automated fact-checking pipelines using tools like FactScore.
- User correction rate: how often do users edit, reject, or re-prompt the model’s output? High correction rates on specific topics point to training data gaps in those areas.
- Retrieval accuracy in RAG systems: how often does the retrieved document actually contain the answer to the query? Low retrieval accuracy means the knowledge base data quality needs improvement.
Build a Continuous Data Improvement Loop
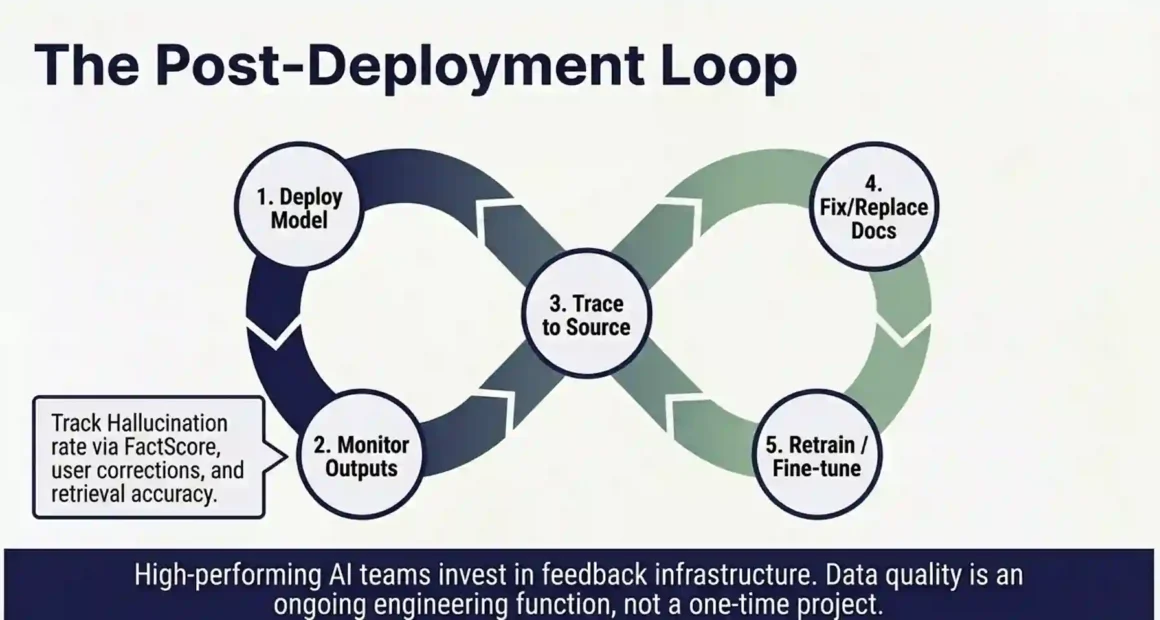
The highest-performing AI teams treat data quality as an ongoing engineering function, not a pre-launch checklist. The loop works like this:
Deploy the model. Monitor outputs. Flag low-quality outputs using both automated metrics and user feedback. Trace those outputs back to the training data or knowledge base documents that caused them. Fix or replace those documents. Retrain or fine-tune on the improved data. Redeploy and repeat.
This loop is what separates AI teams that keep improving model quality over time from teams that launch once and spend the next year firefighting complaints. The investment is in building the feedback infrastructure, not just the model itself.
Master agentic AI testing guide reduce false positives costs. 98% false positive elimination, 50% cost savings via Agent Zero CI/CD. Bulletproof production deployments guaranteed!
Data Quality for Generative AI vs. Traditional ML: Key Differences
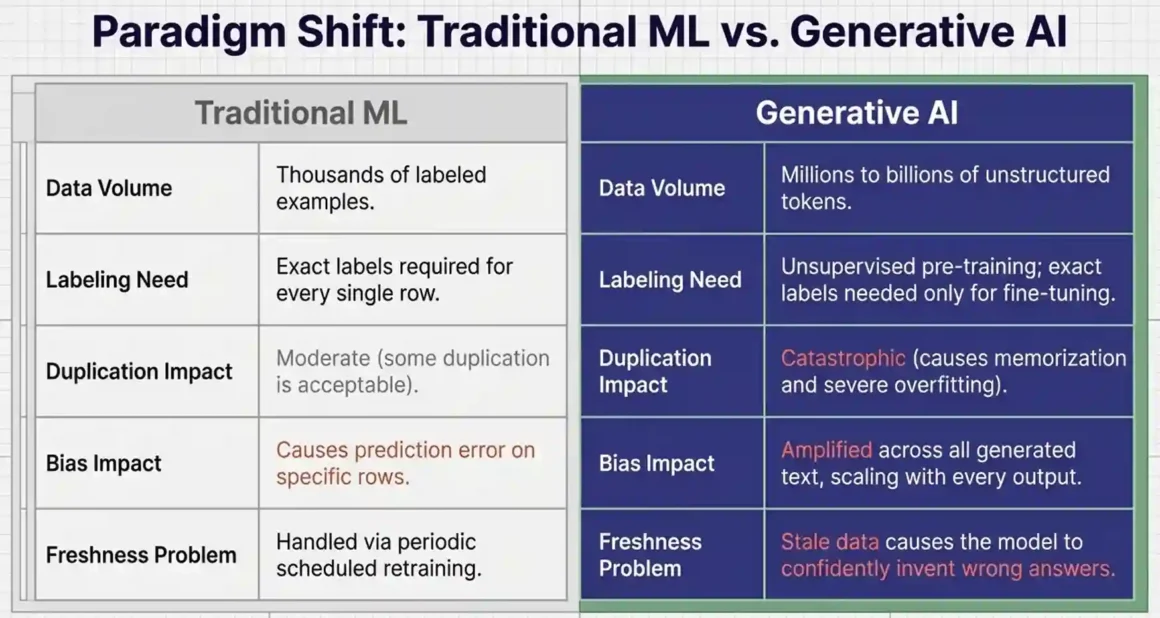
If you come from a traditional machine learning background, some of these data quality requirements might feel familiar. But generative AI introduces specific challenges that are different from classical supervised learning.
| Aspect | Traditional ML | Generative AI |
| Data volume needed | Thousands of labeled examples | Millions to billions of tokens |
| Label precision | Exact labels needed for each row | Labels needed only for fine-tuning; pre-training is unsupervised |
| Duplication impact | Moderate — some duplication is acceptable | High — duplicates cause memorization and overfitting |
| Bias impact | Affects prediction accuracy | Affects all generated text — scales with every output |
| Data freshness | Periodic retraining handles this | Stale training data causes confident wrong answers in LLMs |
| Structured vs. unstructured | Usually structured tabular data | Mostly unstructured text, requiring different cleaning methods |
The scale difference is the most important one. In a traditional ML model that classifies emails as spam or not spam, a few thousand wrong labels in a million-row dataset have a measurable but limited effect. In a large language model trained on billions of tokens, the same quality problems are amplified across every output the model ever produces, to every user, forever.
Practical Data Quality Tools Worth Using
Here are specific tools that solve specific data quality problems in generative AI pipelines. Each one is named, explained, and given a clear use case.
Great Expectations — Data Validation Before Training
Great Expectations is an open-source Python library that lets you write validation rules for your dataset and run them automatically. You define what ‘good data’ looks like — acceptable value ranges, allowed categories, null rate limits — and it flags any violations. Use this at the ingestion stage, before data enters your training pipeline. It catches problems early, when fixing them is cheap.
What NOT to do: do not use Great Expectations as a one-time check. Set it up as a step in your CI/CD pipeline so every new batch of training data is validated automatically before it is added to the training corpus.
datasketch — Near-Duplicate Detection at Scale
datasketch is a Python library that implements MinHash and LSH for fast similarity search. Use it to find and remove near-duplicate documents in large text corpora. It is designed to scale to datasets with millions of documents without requiring pairwise comparison of every document.
Set your similarity threshold based on your task. For general-purpose LLM training, a threshold of 0.8 (documents that are 80% similar) is a reasonable starting point. For domain-specific fine-tuning data where you have limited examples, raise the threshold to 0.95 to avoid removing documents that are similar but distinct.
Label Studio — Annotation with Quality Controls
Label Studio is an open-source data labeling platform that supports text, images, audio, and video annotation. What makes it relevant to data quality specifically is its built-in inter-annotator agreement tracking. You can assign the same data to multiple annotators and see where they disagree — which directly tells you where your annotation guidelines are unclear.
Use Label Studio for any fine-tuning project that involves human labels. Set up agreement dashboards from day one, not after you have labeled everything and found inconsistencies.
Cleanlab — Automated Label Error Detection
Cleanlab is a Python library and platform that uses the model’s own confidence scores to find label errors in your dataset. It works on the principle that if a model trained on your data is very uncertain about a specific example, that example is likely mislabeled. It then ranks all data points by the probability that their label is wrong.
This is particularly useful for large datasets where manual review of every label is not practical. Run Cleanlab after an initial training pass to generate a prioritized list of label errors to fix, then retrain on the cleaned dataset.
Master AI contextual governance business evolution adaptation. Dynamic ethics frameworks enable Agent Zero enterprise scaling. Responsible autonomy adapts to business contexts perfectly!
How Data Quality Affects Specific Generative AI Use Cases
Data quality requirements are not identical across all generative AI applications. The specific dimensions that matter most depend on the use case.
Code Generation Models
For models that generate code (like a GitHub Copilot-style tool), accuracy and correctness of the training data is the dominant concern. Code that does not run, code with security vulnerabilities, or code that is syntactically correct but logically wrong all teach the model bad patterns.
Training data for code generation should be filtered to include only code that passes compilation or syntax checks. Ideally, code should also pass basic unit tests where those are available. Repositories with known security vulnerabilities (identified via CVE databases) should be flagged and either removed or labeled to prevent the model from learning those patterns.
Customer Service AI
For customer service applications, completeness and timeliness are the most critical dimensions. A model trained on chat logs that include unresolved tickets, outdated product information, or deprecated policies will confidently give customers wrong answers.
Before using historical support data for fine-tuning, filter to include only conversations where the issue was marked as resolved and the customer confirmed satisfaction. Tag all product and policy references with version numbers and expiry dates so they can be removed or updated as products change.
Medical and Legal AI
In high-stakes domains like healthcare or legal services, accuracy and source authority are non-negotiable. A model that generates plausible-sounding but medically incorrect information can cause direct harm.
Training data for these domains must come exclusively from authoritative, peer-reviewed, or legally verified sources. Every source must be logged with its origin, date, and author credentials. Any document from an unverified source should be excluded, regardless of how useful its content appears. The risk of including one wrong document at scale is far greater than the benefit of marginally more training examples.
Explore AI propagation modelling. Agent Zero simulates 5G networks, wireless optimization. Real-time telecom planning revolutionized with autonomous AI agents!
Data Governance: Making Data Quality a System, Not a One-Time Fix
All the steps above are effective in isolation. But they only deliver sustained results if they are embedded in a data governance system — a set of repeatable processes, ownership assignments, and quality standards that apply to all data entering the AI pipeline.
Assign Data Ownership
Every dataset used in an AI pipeline should have a named owner — a person or team responsible for its quality. Without ownership, data quality degrades over time because nobody has a reason to maintain it. The owner is responsible for running validation checks, responding to quality alerts, and updating or removing outdated data.
Write a Data Quality Standard for Each Dataset
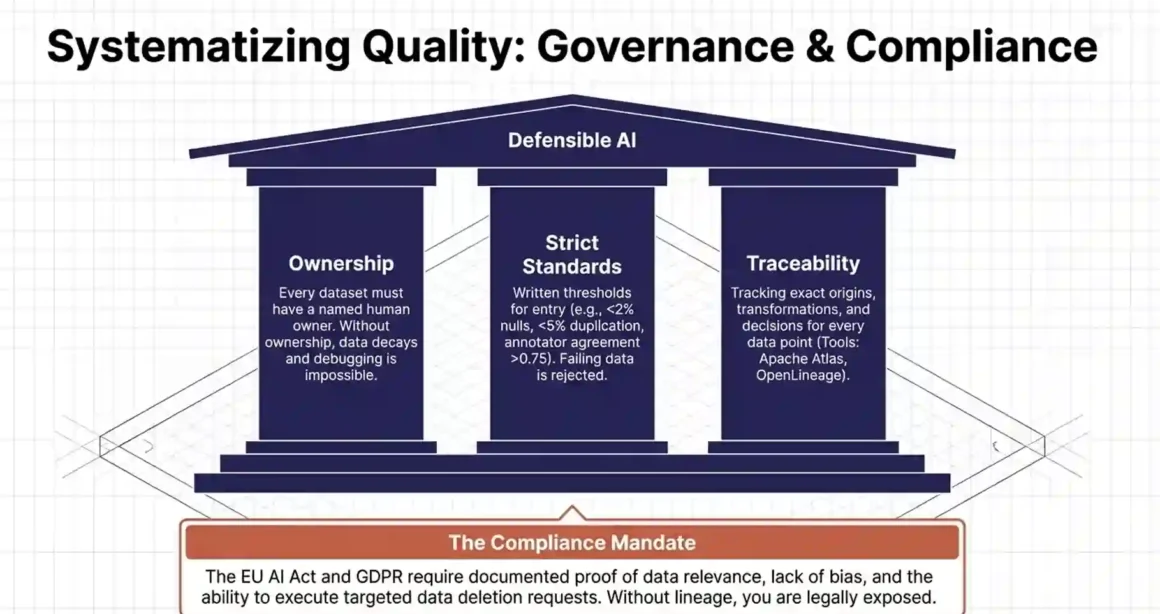
A data quality standard is a document that specifies the minimum acceptable quality thresholds for a specific dataset. For example: the customer support dataset must have less than 2% null values in the resolution field, a deduplication rate of less than 5%, and an inter-annotator agreement above 0.75 for sentiment labels. Any batch of data that does not meet these thresholds is rejected and sent back for remediation before entering the training pipeline.
Track Data Lineage
Data lineage means knowing exactly where every piece of training data came from, when it was collected, how it was transformed, and what decisions were made at each stage. This is essential for two reasons.
First, when a model produces wrong outputs, data lineage lets you trace the problem back to its source and fix it efficiently. Without lineage, you are debugging blindly. Second, when regulations or compliance requirements change — like GDPR data deletion requests or industry-specific data use restrictions — lineage lets you identify and remove affected data from training sets without guessing.
Tools like Apache Atlas, OpenLineage, and Marquez provide data lineage tracking for ML pipelines at different scales.
The Link Between Data Quality and AI Compliance
Regulators are increasingly focused on AI systems. The EU AI Act, which became enforceable in 2024, includes specific requirements for data governance in high-risk AI systems. These include requirements for training data to be relevant, representative, and free of errors to the extent possible, and for organizations to document their data quality practices.
This is not just a legal issue. It is a reputational one. A generative AI product that produces biased, inaccurate, or harmful outputs — traceable to poor training data — creates liability for the organization deploying it. Investing in data quality is also investing in defensibility: the ability to demonstrate, with documentation and audit trails, that you took reasonable steps to ensure your AI system was trained responsibly.
| What auditors and regulators will ask about your training data1. What is the source of each dataset used in training?2. How were bias and representativeness evaluated?3. What validation checks were applied before training?4. How are data quality standards documented and enforced?5. What is the process for removing data upon a deletion request?If you cannot answer these questions with specific documentation, your data governance is not sufficient for regulated industries. |
The Practical Summary: What to Do and What to Avoid

Everything in this article comes down to a set of concrete decisions. Here is the summary.
| What to Do | What NOT to Do | Why It Matters |
| Audit data quality before training | Skip auditing because the data ‘looks okay’ | Most quality problems are invisible without analysis |
| Deduplicate at document and n-gram level | Remove all similar documents without threshold review | Duplication causes memorization; over-deduplication shrinks useful data |
| Write specific annotation guidelines | Use vague label definitions | Vague guidelines produce inconsistent labels the model cannot learn from |
| Score data by source quality | Treat all sources equally | Low-quality sources teach bad patterns that generalize |
| Build a continuous monitoring loop post-deployment | Treat data quality as a pre-launch checklist only | Deployed models degrade as the world changes and data ages |
| Assign data ownership and track lineage | Let datasets have no clear owner | Without ownership, data quality degrades and debugging becomes impossible |
Generative AI is a technology that amplifies what it learns. Give it accurate, clean, representative, well-labeled, and current data — and it amplifies good patterns into useful outputs. Give it noisy, biased, duplicated, and inconsistent data — and it amplifies those problems into every response it ever generates.
The teams that get this right are not the ones with the best models. They are the ones who spent the time on the data before anyone touched the model.









