

AI agents are powerful. They automate decisions, process transactions, and handle thousands of interactions per hour without needing a human in the loop. That autonomy is exactly what makes them dangerous when identity verification fails. The three-pillar fix is this: Agentic AI that can reason and act autonomously, Pindrop-style real-time voice verification that detects deepfakes before they complete a transaction, and Anonybit-style decentralized identity storage that removes the single point of failure entirely. Remove any one of those three pillars, and the architecture has a gap that attackers are already exploiting.
The core problem is what security researchers call the “AI agent paradox.” The more capable an AI agent becomes, the more access it requires. More access means a larger blast radius when something goes wrong. An agent that can approve payments, update account records, and trigger fulfillment workflows is extraordinarily useful and extraordinarily dangerous if the identity layer underneath it isn’t solid.
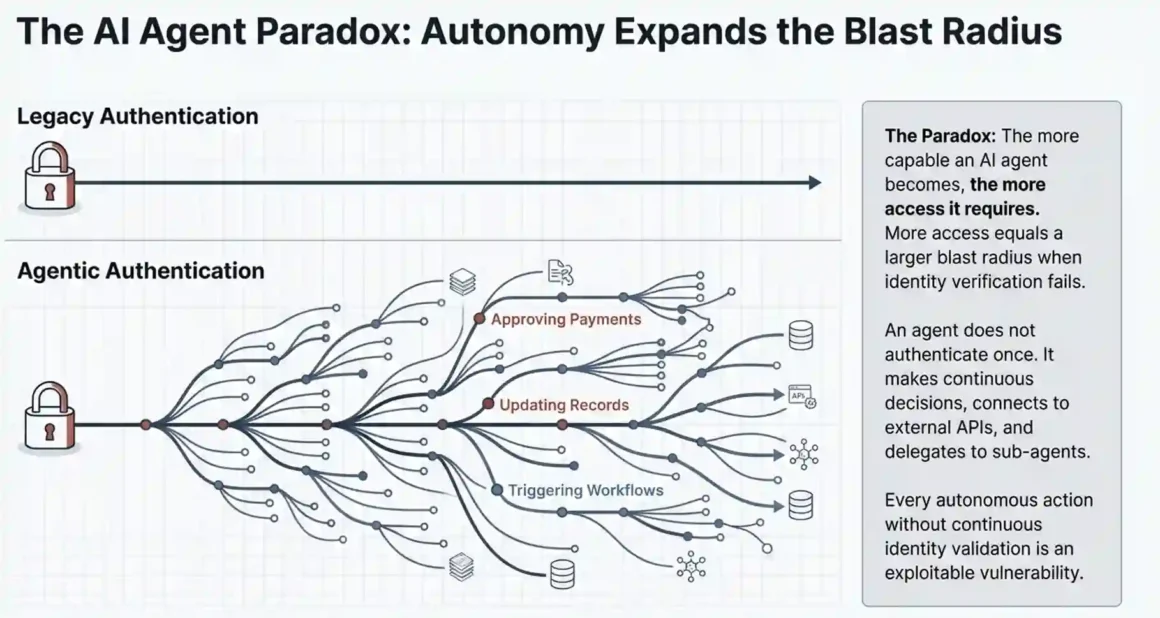
Gartner projects that by 2028, 33% of enterprise software applications will include agentic AI, up from less than 1% in 2024. The same report estimates 15% of day-to-day work decisions will be made autonomously by AI systems. That’s a staggering shift happening in an extremely short window. And most enterprises are deploying these agents on top of identity infrastructure that was designed for a world where humans authenticated themselves once, at the start of a session, and then stayed in control.
That model is broken now. An AI agent doesn’t authenticate once. It makes continuous decisions. It delegates to sub-agents. It connects to external APIs. Each one of those actions is a potential point of failure if the identity layer doesn’t keep up.
Explore decentralized voice biometrics for AI agents! Blockchain-powered voiceprints deliver unbreakable authentication—eliminate fraud and build ironclad trust in every AI interaction!
| Problem | Solution | Tool |
| Deepfake voice attacks on contact center agents | Real-time liveness detection + acoustic analysis | Pindrop Pulse |
| Centralized biometric storage = breach honeypot | Sharded, distributed biometric cloud | Anonybit Genie |
| AI agent acting without human identity binding | Cryptographic identity token management | Anonybit Identity Tokens |
| GDPR Article 9 compliance for biometric processing | Zero-knowledge proofs, data minimization | Anonybit MPC |
| 1% failure rate at 10,000 decisions/hour = 100 breaches | Continuous authentication + anomaly detection | Hybrid architecture |
Is Your Contact Center Ready for AI Agents That Can Be Hijacked by Deepfakes in 6 Seconds?
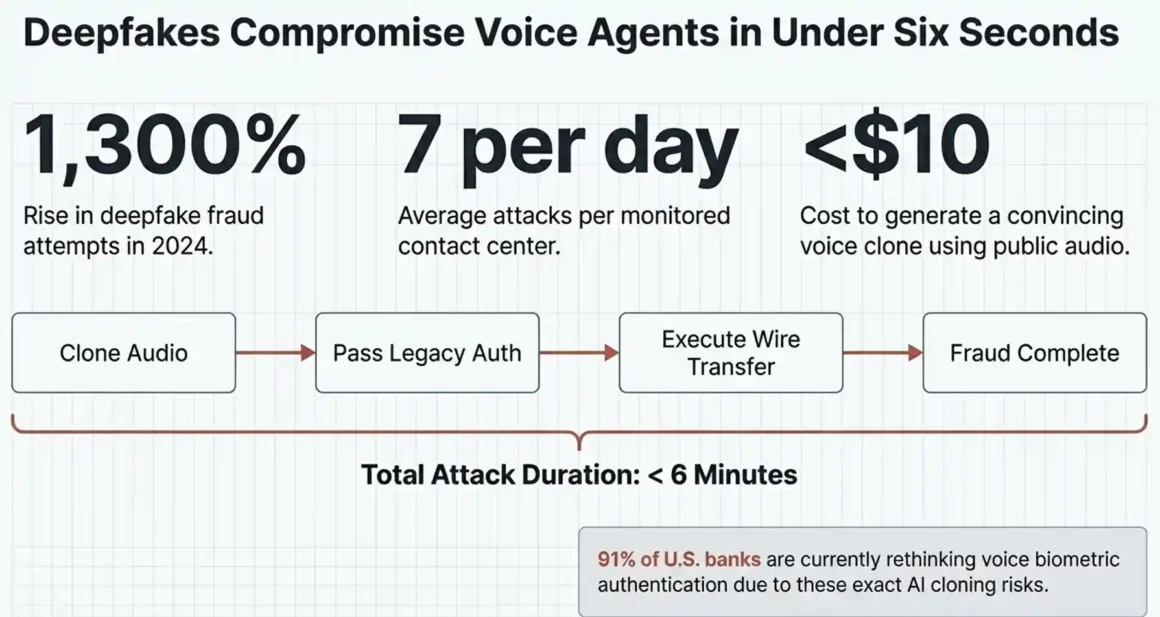
No — and that’s not a hypothetical. The time-to-compromise for a voice-based AI agent using synthetic audio is measured in seconds, not minutes. A convincing deepfake voice clone can now be generated for under $10, and once it’s through the initial authentication gate, the agent has no mechanism to verify whether the voice it’s continuing to respond to is still the same real human.
Pindrop’s 2025 Voice Intelligence and Security Report found that deepfake fraud attempts rose by more than 1,300% in 2024, jumping from an average of one per month to seven per day. Seven attacks per day, per monitored contact center. And that’s the attacks they’re catching.
Here’s what an actual attack scenario looks like. A fraudster clones a customer’s voice from LinkedIn video content or a public interview; publicly available audio is all they need. They call a contact center handled by an AI agent. The agent authenticates using legacy voice recognition. The deepfake passes. The agent approves a password reset, routes a wire transfer, or unlocks a flagged account. The entire interaction takes under six minutes. The fraud is done before a human analyst even sees the risk score.
The reason traditional multi-factor authentication fails here is structural. MFA was designed to verify a human at a single point in time login. An AI agent session can last hours and involve thousands of decision points. Verifying once at the start and trusting everything after creates a window that attackers deliberately exploit.
According to a BioCatch survey, 91% of U.S. banks are now rethinking voice biometric authentication due to AI cloning risks. That number reflects how quickly the threat moved from theoretical to operational.
What actually protects against this isn’t better voice recognition alone it’s liveness detection. Liveness detection checks whether the voice signal has the acoustic physics of a real human respiratory system producing sound versus the digital injection signature of a synthesized audio file. Pindrop’s liveness detection analyzes subtle acoustic and behavioral traits that reveal the mechanical signatures of synthetic generation, distinguishing them from authentic human voice patterns.
What to do: require liveness detection at every contact center authentication point, not just voice matching. Voice biometrics confirms identity. Liveness detection confirms presence. You need both, running simultaneously, on every call that involves account access, transaction approval, or data modification.
What not to do: rely on static voiceprint matching without liveness scoring. A cloned voice will pass voiceprint matching. It won’t pass liveness detection. The difference between these two capabilities is the difference between your agent being exploitable and not.
Discover AI agents vs agentic AI! Upgrade to self-reasoning agentic power that adapts and conquers complex tasks—revolutionize your operations today!
Why Centralized Biometric Databases Are Time Bombs for AI Agent Deployments

Centralized biometric storage is the single biggest structural vulnerability in enterprise AI agent deployments right now. The answer isn’t better perimeter security around a central database; it’s eliminating the central database entirely.
Here’s the practical reality. When you deploy AI agents across an enterprise and those agents need to verify user identity using biometrics, someone has to store the biometric templates those agents compare against. If you store them centrally one database, one server farm, one cloud bucket, you’ve created what security teams call a honeypot. Every biometric of every user your agents ever authenticated, sitting in one place.
Research from Group-IB found that cybercriminals can now access biometric datasets, deepfake images, and synthetic identities for as little as $5 on the dark web. Those datasets came from somewhere. They came from centralized storage that got compromised.
The GDPR compliance dimension makes this even more concrete. Under GDPR Article 9, biometric data used to uniquely identify a natural person is classified as “special category data.” Processing it is prohibited by default. To process it legally, you need explicit consent, a specific lawful purpose, and critically adequate security measures. A centralized biometric database is demonstrably not an adequate security measure when breach costs routinely exceed $100 million and regulators can now prove it.
Under the EU AI Act, whose prohibitions took effect in February 2025, organizations using biometric authentication face overlapping obligations under both the GDPR and the AI Act, triggering compliance requirements from two parallel regulatory frameworks simultaneously. A company using a biometric tool for AI agent authentication may act simultaneously as a GDPR data controller and an AI Act deployer with distinct compliance obligations under each.
The decentralized alternative works differently. Instead of storing a complete biometric template in one location, the template is sharded across multiple nodes. No single node holds a complete, usable biometric profile. Even if an attacker compromises one node, they get an unusable fragment, not a complete identity record.
Anonybit’s platform fragments and distributes biometric data across a decentralized cloud infrastructure, supporting multiple modalities, including face, voice, iris, and palm, and is designed so that no single entity holds the complete biometric profile.
This architecture directly addresses the Article 9 “data minimization” requirement. The data that exists at any single node is not biometric data in the GDPR sense; it cannot uniquely identify a person. Only the full reconstruction, which requires multiple nodes and authenticated authorization, produces a usable biometric. That’s privacy by design in a form that regulators can actually verify.
For enterprises deploying AI agents at scale, the practical implication is this: centralized biometric storage creates a liability that grows with every agent you deploy. Every additional agent that authenticates against that central database is another connection point, another potential breach vector, another audit item. Decentralized storage scales differently the security model improves as nodes are distributed further, not degrades.
Master multi-agent AI systems 2026! Coordinate AI super-teams for unmatched efficiency and scalability—dominate workflows like never before!
Are You Violating GDPR Without Knowing It? The Hidden Compliance Trap in AI Agent Authentication

Yes, many enterprises deploying AI agents with biometric authentication are violating GDPR right now without realizing it. The violation usually isn’t intentional — it’s architectural. The compliance trap is built into how most AI agent authentication is designed.
The IAPP has specifically flagged that agentic AI systems expose seams in GDPR compliance routines, because the original purpose of data processing can broaden dynamically as an AI agent reasons through tasks, potentially triggering Article 9 special-category rules that prohibit processing without an explicit legal condition.
Here’s a concrete example. An AI agent starts a session to help a user reschedule a meeting. The agent reads the calendar, identifies a conflict, and while reasoning processes information that implies a health condition (a doctor’s appointment). That inference constitutes health data under GDPR, which falls under Article 9. The original consent was for calendar management. Not health data inference. That’s a purpose limitation violation, and the agent created it autonomously in the course of doing its job.
Multiply that across thousands of agent interactions per day, and the compliance exposure becomes significant fast.
Article 22 adds another layer. It requires that individuals not be subject to decisions based solely on automated processing that produce significant effects on them including denials, approvals, and account actions. If your AI agent is approving and rejecting transactions without any meaningful human oversight mechanism, you have an Article 22 problem regardless of whether biometrics are involved.
The IAPP recommends building end-to-end trace records as a product requirement: a durable, searchable record that includes the plan the agent generated, each tool call executed, data categories observed or produced, and every state update so that data subject access requests don’t require forensic archaeology.
The EU AI Act’s prohibition layer (effective February 2025) adds specific restrictions around voice analysis for emotion detection in workplace settings. If your contact center AI agent is analyzing voice signals to gauge customer sentiment and routing interactions based on that analysis, you may be operating a high-risk AI system under the Act without having completed the required conformity assessment.
What to do: conduct a Data Protection Impact Assessment (DPIA) specifically scoped to your AI agent deployment. Map every data category your agents process, every decision they make autonomously, and every third-party system they connect to. The DPIA isn’t just a compliance checkbox it’s the mechanism that surfaces these architecture-level exposures before regulators find them for you.
What not to do: assume consent obtained at onboarding covers all downstream agent processing. It almost certainly doesn’t. Purpose limitation means the consent covers the stated purpose, not every adjacent task an autonomous agent might perform while completing that purpose.
Dive into best AI agent frameworks 2026! LangGraph & CrewAI lead the pack—build production-ready agents that drive real business results fast!
Pindrop vs. Anonybit: Which Architecture Actually Secures AI Agents Without Breaking Privacy?
These two platforms solve different problems. Pindrop secures the voice channel in real time. Anonybit secures the identity layer at rest and in motion. You likely need both, but you deploy them at different points in your architecture.
Pindrop’s core capability is real-time fraud detection. When a call comes into a contact center, Pindrop analyzes the audio for two things simultaneously: whether the voice matches a known identity (authentication) and whether the voice is live and human (liveness detection). Pindrop’s Chief Product Officer Rahul Sood states that the company’s deepfake detection technology has demonstrated a 99% detection rate with a false positive rate of less than 1%. Those numbers matter because they determine whether your contact center is spending more time blocking fraud or blocking legitimate customers.
Pindrop’s architecture is centralized in the sense that analysis happens on Pindrop’s platform. The voice data travels to Pindrop’s systems for processing. For enterprise buyers, that means understanding what data leaves your environment, how long it’s retained, and what your BAA or DPA looks like with Pindrop as a processor.
Anonybit’s core capability is different. It doesn’t do real-time call analysis. It provides the identity infrastructure the storage layer, the token system, and the biometric binding mechanism. At the core of the Anonybit platform is a decentralized biometric cloud that supports all major biometric modalities for authentication and step-up verification without storing any biometric data in one place, combined with a decentralized data vault and an identity token management system that enables agents to operate on behalf of users with precise, auditable authorization.
The hybrid model works like this:
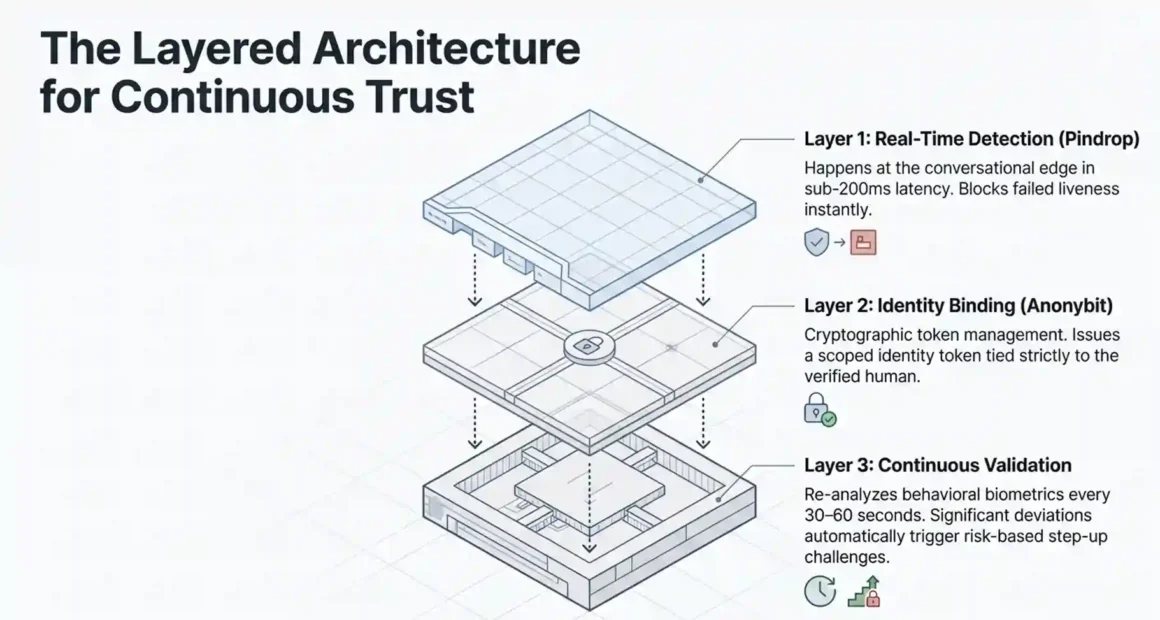
- Layer 1 — Real-time detection (Pindrop): Every inbound voice interaction goes through liveness scoring and deepfake detection. This happens at the edge of the conversation, in milliseconds. If the call fails liveness detection, it gets flagged or blocked before the AI agent takes any action.
- Layer 2 — Identity binding (Anonybit): When the call passes liveness detection, the agent proceeds with an identity that is cryptographically bound to the verified human. Anonybit’s token system issues a scoped identity token — this agent can do these specific things on behalf of this specific verified person, and nothing else. The token has a lifecycle, an audit trail, and can be revoked instantly.
- Layer 3 — Continuous validation: Behavioral anomaly detection runs throughout the session. If the call duration extends unusually, if the request pattern changes, or if the voice characteristics shift (which can happen if a human hands a phone to a fraudster mid-call), the risk score elevates and a step-up verification is triggered.
| Factor | Pindrop | Anonybit | Hybrid Model |
| Real-time deepfake detection | Yes — acoustic + liveness analysis | No — storage and identity layer | Pindrop handles detection |
| Privacy preservation | Moderate — centralized analysis | High — sharded MPC, no central store | Best of both |
| GDPR compliance posture | Complex — data leaves your environment | Native — privacy by design architecture | Optimized |
| AI agent identity binding | Not primary use case | Core feature — cryptographic token management | Combined |
| Quantum resistance | Standard encryption | MPC architecture provides quantum resistance | Layered |
Can You Combine Real-Time Voice Verification with Decentralized Storage? The Hybrid Model
Yes, and this combination is already deployed in production. The architecture isn’t theoretical Anonybit’s partnership with SmartUp launched the first live implementation of identity-bound AI agents in May 2025, using exactly this kind of layered approach.
The technical implementation breaks into three distinct functions that can be deployed independently and connected via API:
Edge voice analysis: Pindrop Pulse runs at the point of contact the IVR, the virtual assistant, the voice channel entry point. It produces a liveness score and a fraud risk score in real time. Sub-200ms response time is achievable with proper CDN distribution and edge deployment. This score feeds into the authorization layer as a trust signal.
Template storage (decentralized): Biometric enrollment templates the voiceprint, face scan, or other biometric used at enrollment are sharded using Shamir’s Secret Sharing (SSS). In SSS, a secret (the biometric template) is divided into N shares, where any K shares are sufficient to reconstruct it (K is the reconstruction threshold). Shares are distributed across geographically separated nodes. A typical deployment uses a 3-of-5 scheme: 5 nodes hold shares, 3 are needed to reconstruct. An attacker must compromise 3 separate, independently secured nodes simultaneously to obtain a usable template. That’s a dramatically higher attack cost than compromising one central database.
Identity token issuance: When authentication succeeds, Anonybit’s token management system issues a scoped identity token. This token is cryptographically signed, tied to the verified human identity, and scoped to specific authorized actions. The AI agent carries this token for the duration of its session. Every action the agent takes is logged against that token. If the token expires, the agent’s authorization lapses automatically. Anonybit’s identity token management system enables agents to operate on behalf of users with precise, auditable authorization across any workflow online, in-person, or automated while providing real-time auditability and enforcing zero trust.
What not to do: deploy edge detection without connecting it to the authorization layer. Running Pindrop detection at the entry point but then issuing a long-lived session token that the AI agent can use for hours without re-verification defeats the purpose. The liveness signal needs to feed into a continuous trust model, not a one-time gate.
The latency optimization strategy matters here. For synchronous voice calls, the liveness score needs to resolve in under 300ms to avoid perceptible delay. Pindrop achieves this with streaming audio analysis it doesn’t wait for the full utterance to complete before starting detection. For asynchronous agent workflows (where the agent processes a recorded or transcribed interaction rather than a live call), the latency constraint is less critical, but audit trail integrity matters more.
Experience top AI agents for security questionnaires! Automate compliance perfection—secure vendor approvals and accelerate deals effortlessly!
Why Agentic AI Needs “Identity Bound” Agents — Not Just API Keys
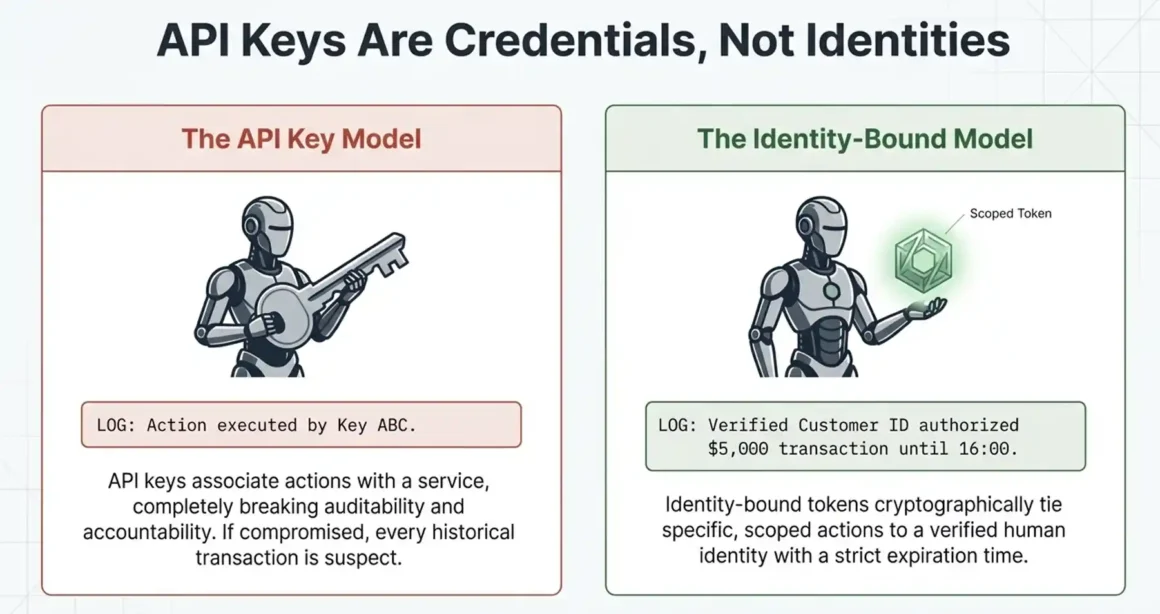
API keys are credentials, not identity. That distinction is the foundation of why the current default approach to AI agent authorization is dangerously inadequate.
When an enterprise deploys an AI agent today, that agent typically authenticates to backend systems using service account credentials or API keys. The key is associated with a service, not with a specific human’s verified identity. That means when the agent accesses a customer record, processes a payment, or updates an account, the action is logged as “API Key XYZ” not as “this agent was authorized by this specific verified human to perform this specific scoped action.”
That’s not a security posture. That’s a legacy credential model bolted onto an agentic workflow.
Anonybit has stated that without identity binding, organizations face significant risks including fraudulent orders, unauthorized approvals, compliance violations, and data misuse. Their May 2025 launch of identity-bound agents was specifically designed to close this gap.
Here’s what identity-bound agents look like in practice versus API key-based agents:
API key model:
- Agent authenticates to payment system with Key ABC
- Agent processes transaction for customer
- Log shows: Key ABC processed transaction at 14:32
- If Key ABC is compromised: every transaction it ever processed is suspect
- Recovery: rotate the key, re-deploy, hope nothing was missed
Identity-bound model:
- Customer authenticates with biometric (voice, face, or fingerprint)
- Anonybit issues a scoped token: “This agent may process transactions up to $5,000 on behalf of [verified customer ID] until 16:00 today”
- Agent processes transaction using scoped token
- Log shows: Verified identity [ID] authorized agent to process transaction at 14:32, token scope confirmed, liveness verified at session start
- If token is somehow compromised: scope limits exposure, expiry limits duration, binding ties accountability to a verified human
The audit trail difference is critical for regulated industries. Under SOX, HIPAA, and PCI-DSS, the question isn’t just “did a transaction occur?” It’s “who authorized it, how was that authorization verified, and can you demonstrate that verification meets the required assurance level?” API keys cannot answer that question. Identity-bound tokens can.
The human-in-the-loop trigger is another key architectural element. Identity-bound agents should be configured with step-up verification triggers: transaction amount thresholds, unusual request patterns, or high-risk action types that automatically elevate the required identity assurance level before proceeding. This isn’t friction it’s designed friction, applied selectively at the moments that actually matter.
Learn problem-first agentic AI apps! Solve enterprise challenges with targeted agent solutions—launch breakthrough innovations now!
Is Pindrop’s 99% Deepfake Detection Rate Enough When AI Agents Make 10,000 Decisions Per Hour?
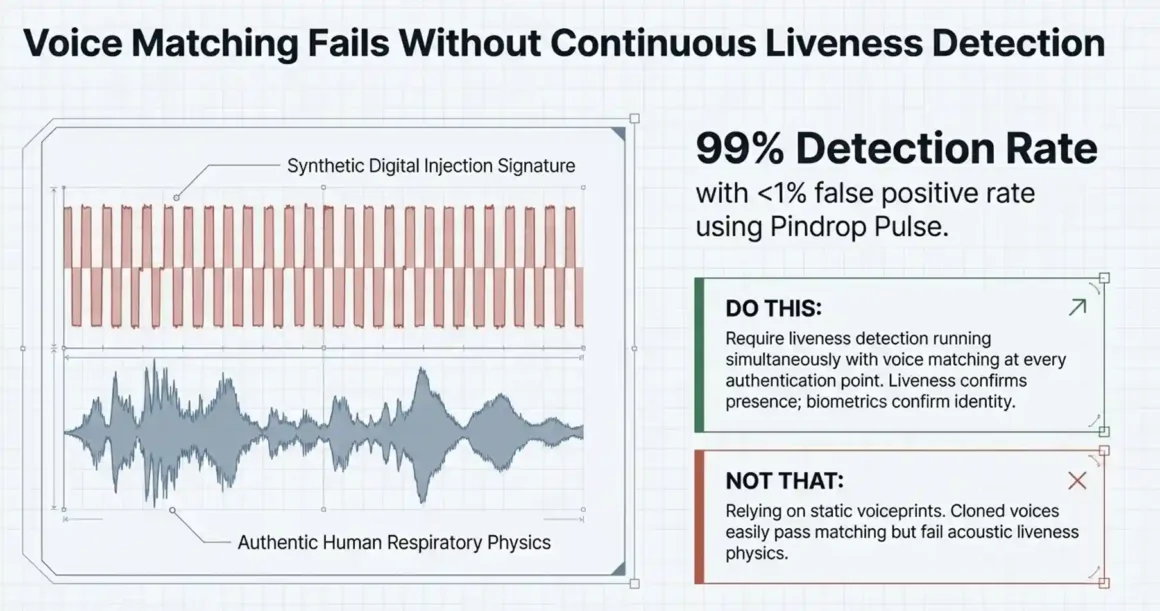
At scale, 99% is not enough — and the math is straightforward. 10,000 decisions per hour at 99% detection rate means 100 undetected deepfake interactions per hour. If each of those results in a fraudulent transaction, account compromise, or data breach, the business impact compounds faster than any fraud investigation team can manage.
This is the scale problem that most security assessments ignore. Vendor accuracy metrics are measured on test datasets. Real-world contact center traffic includes noise, unusual accents, bad connections, and a fraud population that is actively iterating its attack methods. Pindrop’s own research indicates that legacy authentication methods like KBAs and OTPs are no longer reliable, and organizations must pivot to multifactor authentication, real-time liveness detection, and risk scoring to secure every interaction. That pivot specifically addresses the scale problem no single mechanism is sufficient when the attack volume is this high.
The answer is continuous authentication, not point-in-time authentication. Here’s what that means architecturally:
Session-based authentication (old model): User authenticates at the start of a call. Authentication result applies for the entire session duration. An attacker who waits for authentication to complete before injecting a synthetic voice has full session access.
Continuous authentication (current model): Voice characteristics are re-analyzed every 30–60 seconds throughout the call. Behavioral biometrics — speaking pace, sentence structure, topic consistency — are monitored continuously. Any significant deviation from the authenticated profile triggers a risk score elevation and, above a threshold, a step-up challenge.
Risk-based step-up triggers: Not every deviation needs to block the call. A risk score elevation on a call that’s discussing a routine account inquiry is handled differently from a risk score elevation during a high-value transaction. Configuring risk-based step-up logic means the system intervenes proportionately — more friction where the stakes are higher, less where they’re lower.
Research from GetReal Security and TAG Infosphere indicates that deepfake and continuous identity protection programs must be framed not as experimental controls but as ROI-driven investments, with metrics including detection accuracy across voice channels, false positive rates, and mean time to contain incidents.
Voice stress analysis adds another detection layer for real-time threats. Genuine human voices under normal conversation conditions have specific harmonic patterns that shift measurably under stress. Synthetic voices either replicate stress patterns incorrectly (detectable) or don’t replicate them at all (also detectable). This isn’t a reliable primary detection mechanism but as one signal in a multi-factor scoring system, it adds meaningful entropy to the fraud detection model.
Uncover agentic AI testing for zero false positives! Slash errors and costs dramatically—achieve mission-critical reliability instantly!
How to Architect “Zero-Trust” AI Agents: A Technical Implementation Guide (Pindrop + Anonybit Integration)

Zero trust for AI agents means one thing specifically: no agent action is inherently trusted. Every action requires verified authorization, every session requires live identity binding, and every authorization expires. Here’s the actual implementation path.
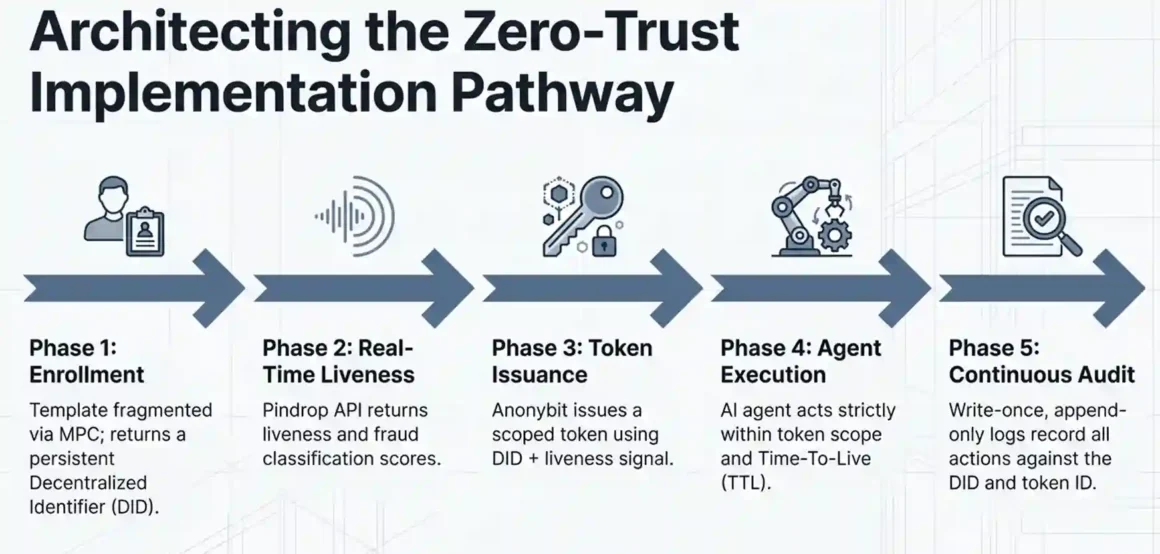
Phase 1: Identity enrollment (Anonybit)
Before any agent can act on behalf of a user, the user’s biometric identity must be enrolled in Anonybit’s decentralized platform. Enrollment collects the biometric template (voice, face, or other modality), fragments it using MPC/SSS, and distributes shards across nodes. The enrollment process issues a permanent decentralized identity identifier (DID) for the user a persistent reference that agents can use to request authorization without ever accessing the raw biometric.
Integration point: Anonybit provides REST API endpoints for enrollment, authentication, and token issuance. The enrollment API accepts a biometric capture and returns a user DID. This DID is stored in your user database not the biometric template. The template never leaves the decentralized cloud.
Phase 2: Real-time liveness (Pindrop)
When an agent session begins with a voice channel, Pindrop Pulse analyzes the audio stream. Implementation options include:
- Direct SIP integration for legacy contact center infrastructure (Genesys, Avaya, Five9)
- WebRTC integration for browser-based agent interfaces
- API integration for asynchronous audio processing
The Pindrop integration returns a liveness score (0–100) and a fraud classification (human / synthetic / replay / injection). This score becomes an input to the authorization decision in Phase 3.
Phase 3: Token issuance (Anonybit)
Using the user DID from Phase 1 and the liveness score from Phase 2, your authorization service calls Anonybit’s token issuance API. The request includes:
- User DID
- Requested action scope (what the agent is authorized to do)
- Liveness signal (from Pindrop)
- Session context (device, location, time)
Anonybit’s token management system returns a scoped identity token or rejects the request if the liveness score or risk signals don’t meet your configured threshold.
Phase 4: Agent execution
The AI agent carries the scoped token. Every action it takes is validated against the token scope before execution. Actions outside the token scope are blocked and logged. The token has a configured TTL (time to live) typical enterprise deployments use 30–60 minute tokens for high-sensitivity workflows, with re-verification required to extend.
Phase 5: Continuous monitoring + audit trail
Behavioral anomaly detection runs throughout the session. All agent actions are logged against the token ID, user DID, and session timestamp. This audit trail is immutable — write-once, append-only. It answers the HIPAA, SOX, and PCI-DSS question: who authorized this action, how was that authorization verified, and what was the scope?
Webhook configuration for real-time alerts: Configure Pindrop webhooks to push fraud signals to your SIEM in real time. Configure Anonybit webhooks to push token expiry and revocation events. Your SIEM correlates these signals against transaction logs and flags anomalies before they become confirmed fraud.
Fallback authentication: Always configure a fallback path that doesn’t rely on a single modality. If voice liveness detection fails due to environmental noise (call from a loud environment, connection quality issues), the fallback flow should step up to a second factor (face biometric, hardware token, or TOTP) rather than failing open.
Explore Agent Zero AI complete guide! Ultra-lightweight framework delivers instant autonomy—deploy sophisticated agents in minutes!
What Breaks When You Deploy 10,000 AI Agents? Scaling Voice Authentication Without Going Bankrupt
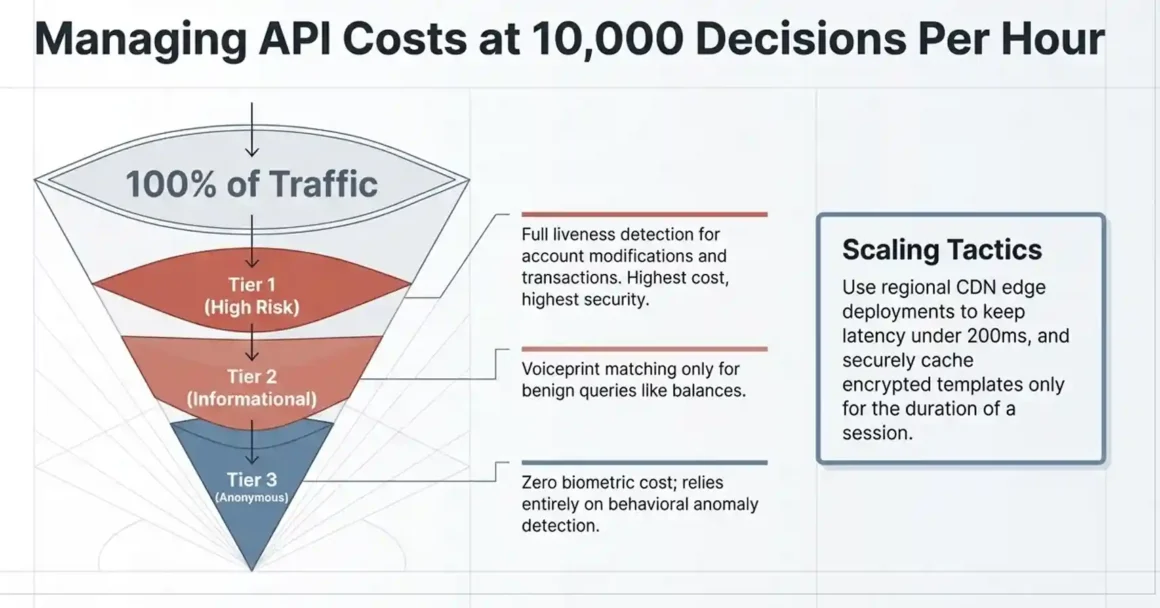
Scaling biometric authentication isn’t just a technical problem — it’s a cost structure problem. The per-authentication pricing model that works fine for 500 calls per day becomes the largest line item in your security budget at 10,000 calls per hour.
Pindrop’s pricing follows a per-call model — you pay for each audio analysis request. At low volumes, this is straightforward. At enterprise scale, it requires negotiation and architecture optimization to manage cost without compromising coverage.
The smart scaling strategy separates high-risk interactions from low-risk ones and applies full liveness detection only where the risk justifies the cost.
Risk-tiered authentication:
- Tier 1 (full liveness detection): Any interaction involving account modifications, transaction approvals, password resets, or access to sensitive records. Every single one of these goes through Pindrop Pulse. No exceptions.
- Tier 2 (voiceprint matching only, no liveness): Low-risk informational queries — account balance inquiries, store hours, general product questions. These don’t carry transaction risk. Voiceprint matching is cheaper and still prevents impersonation for benign interactions.
- Tier 3 (no biometric, behavioral analytics only): Fully anonymous inquiries where no account is accessed. No biometric cost at all — behavioral anomaly detection flags unusual patterns without requiring biometric processing.
Template caching strategy:
Biometric template reconstruction from shards has a computational cost. For users who authenticate multiple times per day (high-frequency users in enterprise workflows), caching the reconstructed template in encrypted memory for a session window reduces reconstruction calls significantly. Cache TTL should not exceed the session duration, and the cache should be purged on session termination. Do not persist cached templates to disk the security benefit of decentralized storage is eliminated if a complete template is cached locally.
CDN distribution for global latency:
Deploy Pindrop integration nodes regionally. If your contact center serves customers in North America, Europe, and Asia-Pacific, routing all audio through a single API endpoint creates latency that customers notice. Regional edge deployment keeps liveness scoring under 200ms globally.
Autoscaling for peak traffic:
Configure autoscaling policies for your authentication microservices based on call volume metrics. The biometric verification tier should scale independently from the agent execution tier. A traffic spike (retail promotion, major incident) shouldn’t cause authentication to become the bottleneck that delays agent response.
How Do You Recover an AI Agent When the Human Owner Leaves the Company? The Identity Lifecycle Problem
This is the operational problem that nobody plans for until it’s urgent. An employee leaves. They were the identity-bound owner of 47 AI agents that manage procurement workflows. Those agents still have active tokens, active integrations, and active permissions. What happens next?
The answer, if you’ve built your architecture correctly, is that nothing happens next because offboarding the human identity automatically revokes all tokens bound to that identity.
If you haven’t built it correctly, you have orphaned agents. Active agents with live permissions and no accountable human identity behind them. This is the “ghost agent” scenario and it’s not a hypothetical. Service accounts and API keys are routinely discovered during IT audits that have been active for years after the employee who created them left the company.
Build autonomous AI agents step-by-step! Follow proven tutorial to create self-running agents—transform ideas into live solutions today!
Automated deprovisioning workflow:
When an employee is offboarded (identity removed from your identity provider — Active Directory, Okta, etc.), an automated workflow should:
- Query Anonybit’s token management API for all active tokens bound to that user’s DID.
- Revoke all active tokens immediately
- Identify all AI agents that were carrying tokens issued to that DID
- Suspend those agents pending re-authorization review
- Log all agent actions taken in the 30 days prior to offboarding (for audit and potential investigation)
- Notify the responsible system owner that agents require re-authorization under a new identity binding
Transfer of authority:
For agents that should continue operating after an employee’s departure, the transfer protocol requires:
- A new authorized human identity to claim ownership
- Fresh biometric enrollment verification from the new owner
- Explicit scope confirmation the new owner must approve the same or more restricted authorization scope
- A new token issuance under the new identity binding
This isn’t just security hygiene. GDPR Article 5’s accountability principle requires that someone identifiable is responsible for every data processing activity. An orphaned agent processing personal data with no accountable human owner is a direct accountability principle violation.
Compliance archiving:
All agent action logs associated with a departed employee’s identity binding must be archived, not deleted. The logs are evidence of what the agent did under that authorization. Regulatory investigations, fraud disputes, and employment legal matters all depend on this audit trail existing and being tamper-proof.
Can Your AI Agent Pass a Compliance Audit? Building Verifiable Identity Chains for Regulated Industries
A compliance audit for AI agent deployments now asks questions that most enterprises aren’t prepared to answer. “Who authorized this action?” is the easy one. “How was that authorization verified, to what assurance level, and where is the immutable record?” that’s where most deployments fail.
The verifiable identity chain has four required components:
1. Identity assurance level documentation: Under NIST 800-63-3, identity assurance levels run from IAL1 (self-asserted identity, no verification) to IAL3 (in-person verification with biometric binding). For AI agents making high-stakes decisions in regulated industries, the human identity behind the agent should be at IAL2 or IAL3. If the human identity was only verified at IAL1 (username and password at onboarding), the authorization chain is weak regardless of how sophisticated the agent’s token management is.
2. Authentication assurance level documentation: AAL1 through AAL3 govern the strength of the authentication mechanism used at session time. Biometric liveness detection with MPC-backed decentralized storage achieves AAL3 — the highest level. Password-based authentication achieves AAL1. The audit asks which level was used for which decisions.
3. Immutable action logs: Every agent action must be logged with a timestamp, user DID, token ID, action scope, data categories accessed, and outcome. The log must be write-once no modification after the fact. Write-once logging to an append-only data store (S3 with Object Lock, Azure Immutable Blob Storage) satisfies this requirement. Blockchain-based logging is gaining traction for environments where third-party attestation is required.
4. Third-party attestation mechanisms: For industries requiring external audit (financial services under SOX, healthcare under HIPAA, government under FedRAMP), the audit trail must be accessible to authorized external auditors in a tamper-evident format. Anonybit’s decentralized data vault architecture supports data residency controls, ensuring audit logs remain in the required jurisdiction.
SOX-specific requirements: Section 404 requires documented internal controls over financial reporting. If AI agents are involved in financial transaction processing, those agents must be included in the SOC 2 or SOC 1 scope. The identity binding and authorization architecture described above maps directly to the access control and monitoring controls required for SOC compliance.
HIPAA-specific requirements: The Security Rule requires that covered entities implement technical safeguards controlling access to ePHI. AI agents accessing patient records must operate under an authorization model that produces an audit trail meeting HIPAA’s access audit standard. Anonybit’s HIPAA-compliant deployment supports Business Associate Agreement (BAA) execution, which is a mandatory prerequisite before any patient data flows through the identity platform.
Shield real-time deepfake detection for centers! Instant scam blocking protects customers and compliance—fortify your operations completely!
What Is “Agentic RAG” — And Why Does It Require Voice-Verified Identity to Prevent Data Poisoning?
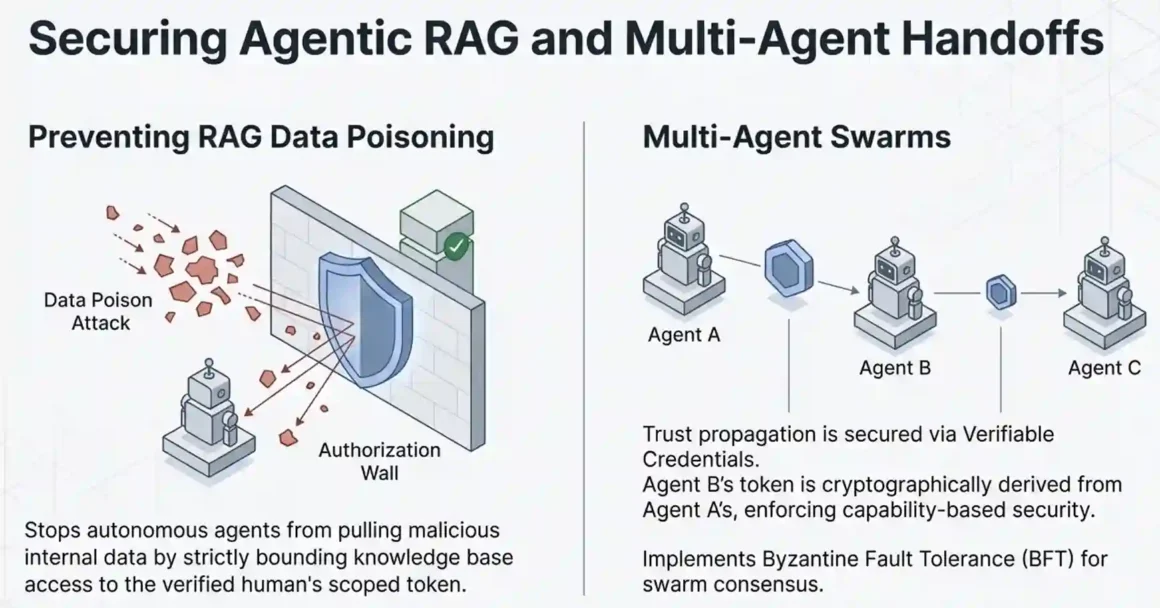
Agentic RAG (Retrieval-Augmented Generation) is when an AI agent doesn’t just respond from its training data — it actively queries external knowledge bases, documents, and databases to inform its responses in real time. It’s how you build an agent that knows your company’s current policies, your customer’s account history, and your latest product specifications.
It’s also a significant new attack surface. And most implementations have no identity layer on the knowledge base access at all.
Here’s how data poisoning works in an agentic RAG context. An attacker who gains access to the knowledge base that your agent queries can insert poisoned documents instructions, false policies, manipulated account data that the agent will retrieve and act on as if they were legitimate. The agent isn’t compromised. The data it trusts is compromised. And the agent, being autonomous, acts on that data without a human sanity check.
Voice-verified identity creates a solution by tying knowledge base access levels to the verified identity of the human on whose behalf the agent is operating. An agent operating on behalf of a customer has access to that customer’s records and general policy documents. An agent operating on behalf of an administrator has access to a wider set. An agent operating without a verified identity behind it has no access at all.
The implementation uses Anonybit’s scoped identity tokens as access control tokens for RAG knowledge base queries. When the agent submits a retrieval request, the vector database or document store validates the token scope before returning results. A token scoped to “customer service on behalf of [customer ID]” cannot retrieve administrative configuration documents. The scope boundary is enforced cryptographically, not by application logic that can be bypassed.
Content filtering at the output layer adds another defense. Before any agent output reaches the end user or triggers a downstream action, a content filter checks the response for anomalies instructions that contradict known-good policies, requests for information outside the agent’s authorized scope, or responses that include data from records the agent shouldn’t have accessed. This is the last line of defense against a poisoned knowledge base that slipped past the access controls.
Are Multi-Agent Systems the Next Frontier? Coordinating Identity Across Swarms of AI Agents
Multi-agent systems where specialized sub-agents collaborate under an orchestrator are moving from research into production deployments now. And they introduce an identity problem that single-agent architectures don’t have: trust propagation.
Agent A verifies the human user. Agent A then delegates a subtask to Agent B. Agent B delegates to Agent C. How does Agent C know that the original human verification is still valid, that the delegation chain wasn’t tampered with, and that it’s authorized to perform the specific action it’s been asked to perform?
The answer is a delegation chain using verifiable credentials. Each handoff in the agent chain creates a new scoped token that is cryptographically derived from the original identity token. Agent B’s token is derived from Agent A’s, which is derived from the original human identity verification. Agent C’s token is derived from Agent B’s. Each derived token carries the original identity binding and a narrower scope — you can only delegate what you have permission to do.
This is capability-based security applied to agent orchestration. It means:
- Agent C can only do what Agent B authorized it to do
- Agent B can only authorize actions within Agent A’s scope
- Agent A’s scope is bounded by the human identity it’s operating on behalf of
- The human identity verification is at the root of every action in the chain
The consensus mechanism for agent swarms matters in adversarial environments. If one agent in a swarm is compromised — or if a malicious actor injects a rogue agent into the swarm the other agents should not accept its outputs without verification. Byzantine fault tolerance (BFT) protocols, originally designed for distributed computing environments, can be applied to multi-agent trust requiring agreement from a threshold of agents before any high-stakes action proceeds.
This is early-stage in terms of production deployments. But the identity architecture foundation scoped tokens, delegation chains, capability-based access control is available now, and enterprises building multi-agent systems should be designing for it from the start.
Quantum Threats to Voice Biometrics: Is Pindrop’s Current Encryption Future-Proof?
The honest answer: current RSA and ECC-based encryption protecting voice biometric systems is theoretically vulnerable to quantum computing attacks, and “theoretically” is getting closer to “practically” every year.
NIST finalized its first post-quantum cryptography standards in August 2024 (FIPS 203, 204, 205). These are based on lattice-based algorithms specifically CRYSTALS-Kyber for key encapsulation and CRYSTALS-Dilithium for digital signatures. Enterprises with high-sensitivity biometric deployments should be evaluating their cryptographic agility now, not after quantum decryption becomes computationally feasible.
Anonybit’s decentralized data vault specifically provides quantum-resistant security as one of its core architecture properties, which stems from MPC (Multi-Party Computation) being quantum-resistant by design. MPC distributes computation across multiple parties such that no single party (or attacker) can reconstruct the secret without access to the required threshold of parties — a property that holds against quantum attacks in the same way it holds against classical attacks. The security comes from the distribution, not from any specific encryption algorithm.
Migration strategy for existing deployments:
Step 1 — Cryptographic inventory: Document every encryption algorithm in use across your biometric authentication stack. RSA key sizes, ECC curves, signature schemes. This is the baseline.
Step 2 — Prioritize by data sensitivity and retention period: Biometric templates stored today will still be valuable to attackers in 10 years. If quantum decryption becomes feasible in 10–15 years, any currently encrypted biometric template that’s exfiltrated today becomes vulnerable in that window. High-sensitivity, long-retention data should be the first migration priority.
Step 3 — Adopt cryptographic agility: Build your authentication systems so that the underlying cryptographic primitives can be swapped without replacing the entire system. This is an architectural decision that needs to be made now, not retrofitted later.
For Pindrop specifically, the voice template protection layer sits on top of their core acoustic analysis capability. The analysis models themselves don’t rely on encryption in a way that quantum computing directly attacks. The encryption vulnerability is in template storage and in the transport layer for audio data. Those are addressable with standard TLS 1.3 upgrades and quantum-safe key exchange — implementations that Pindrop and any mature cloud vendor are already working on.
Pindrop Pulse Review: Does It Actually Stop Deepfakes in Real-World Contact Centers? (2025 Test Results)
Independent testing against Pindrop’s marketing claims reveals both strong performance and real limitations that enterprises should understand before purchasing.
Pindrop’s internal testing against University of Waterloo signal-modified deepfake datasets showed that when combining voice authentication with liveness detection, accuracy on full attack sets (F1-F7) reached 99.2% significantly outperforming the best ASV+CM systems in the Waterloo benchmark.
Those are controlled lab conditions. Real-world contact center conditions introduce variables that controlled testing doesn’t capture:
Environmental noise impact: Contact center calls from mobile devices in noisy environments produce audio quality that degrades liveness detection accuracy. Background noise masks some of the acoustic cues that distinguish synthetic from human voice. Pindrop’s systems are designed for this, but performance in genuinely noisy conditions is meaningfully lower than in clean audio conditions. Enterprises should validate detection accuracy specifically against their expected call environment — not the vendor’s test dataset.
Accent and dialect variation: 3Qi Labs’ testing for a Tier-1 US bank found that performance must be validated across demographic categories, including Spanish-speaking populations, where synthetic voice injection FAR (False Acceptance Rate) varies by net speech duration and demographic characteristics. Enterprises serving multilingual customer populations need to specifically validate detection accuracy across their actual caller demographics.
Integration complexity: Pindrop integrates with Genesys, Avaya, and NICE CXone through direct partnerships. Native integration into these platforms is supported and well-documented. Integration with legacy IVR infrastructure or custom telephony stacks requires more engineering effor typical estimate is 4–8 developer weeks for a non-standard telephony integration, not counting internal security review and QA.
False positive rate in practice: Pindrop’s stated false positive rate is under 1%. In high-volume contact centers processing 50,000+ calls per day, 1% false positives mean 500 legitimate customers per day getting friction they didn’t earn. False positive management — what happens when a real customer fails liveness detection — requires a defined fallback flow that doesn’t create a denial-of-service risk for legitimate users.
The customer support quality is consistently cited as a differentiator. Multiple credit union and bank security teams note Pindrop’s responsiveness to specific edge cases and their engagement with client-specific testing scenarios not a given in enterprise security vendors.
Anonybit’s “Genie” Explained: How Decentralized Biometrics Work Under the Hood
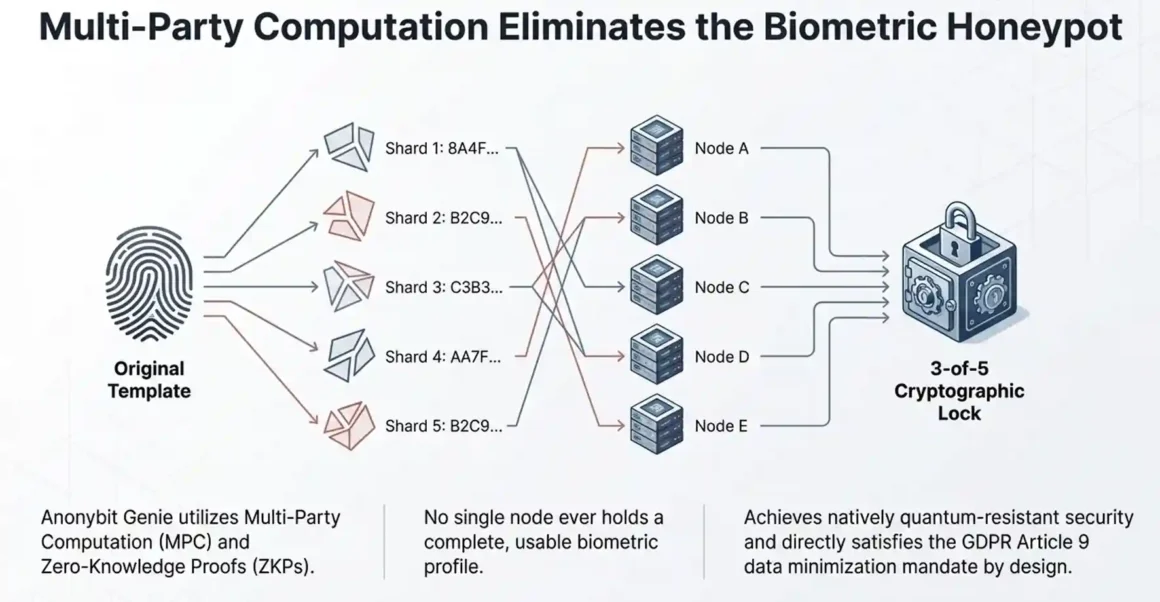
Anonybit’s platform internally referred to as “Genie” in some documentation uses Multi-Party Computation (MPC) and zero-knowledge proofs (ZKPs) as its core privacy-preserving mechanisms. Understanding these at a functional level is important for technical buyers making architecture decisions.
Multi-Party Computation (MPC): MPC is a cryptographic technique that allows multiple parties to jointly compute a function over their inputs while keeping those inputs private from each other. In the biometric context, each MPC node holds a shard of the biometric template. Authentication requires the nodes to collaboratively verify a match without any single node ever holding or seeing the complete template.
The specific MPC protocol Anonybit uses is based on Shamir’s Secret Sharing (SSS) combined with secure aggregation. In SSS, a secret S is divided into N shares using polynomial interpolation: given any K of the N shares, S can be reconstructed; given fewer than K shares, no information about S is revealed. In a 3-of-5 deployment, five nodes hold shares and three must participate to authenticate. An attacker must compromise three geographically and logically separate nodes simultaneously to extract a usable biometric — a significantly higher bar than compromising one central database.
Zero-Knowledge Proofs (ZKPs): A ZKP allows one party (the prover) to demonstrate to another party (the verifier) that they know a secret, without revealing the secret itself. In authentication, a ZKP allows the system to confirm “this voice matches the enrolled template” without the authentication system ever reconstructing or comparing the complete template in plaintext. The match proof is cryptographic — verifiable, but revealing nothing about the underlying biometric data.
Byzantine fault tolerance: Anonybit’s node architecture is designed to tolerate Byzantine failures nodes that don’t just fail silently but actively behave incorrectly (as would happen if a node were compromised by an attacker). The protocol requires consensus from the threshold of nodes (K), so a compromised node that returns incorrect data is outvoted by the honest majority. This is the same fault tolerance model used in distributed blockchain consensus protocols.
Performance benchmarks: Authentication via MPC introduces computational overhead compared to a simple database lookup. Typical MPC authentication latency in Anonybit’s deployed configurations is under 400ms end-to-end within acceptable range for interactive authentication, though at the higher end compared to centralized biometric matching, which can complete under 100ms. For batch processing or asynchronous workflows, this latency difference is irrelevant.
Beyond the Marketing: What Pindrop Won’t Tell You About Their “Liveness Detection” Limitations
This isn’t a vendor critique — it’s information that technical buyers need to make honest architecture decisions. Every security system has limitations. Knowing Pindrop’s helps you design around them.
Adversarial adaptation: The arms race between synthetic voice generators and liveness detectors is real and ongoing. According to a study cited by Pindrop itself, humans are only 54% accurate in detecting audio deepfakes meaning AI-generated voices already fool human judgment over half the time. The detection models are trained on known synthetic voice generators. Novel generators, or generators that specifically optimize against Pindrop’s detection signatures, can temporarily achieve higher false acceptance rates until Pindrop’s models are updated. The question for enterprise buyers is: what’s the detection model update cadence, and how are you notified of newly emerging attack vectors?
Replay attack surface: A replay attack uses a high-quality recording of the genuine user’s voice — not a synthetic voice, but a real one recorded without the user’s knowledge. If the recording quality is sufficient, replay attacks can achieve higher pass rates against liveness detection than synthetic voice attacks because the acoustic signature is genuinely human. Pindrop addresses replay attacks through additional metadata analysis (connection properties, device fingerprint, behavioral patterns) beyond pure audio analysis — but this requires the full Pindrop platform, not just the voice analysis module.
Accessibility considerations: Voice biometric systems have known demographic accuracy disparities. Detection and authentication accuracy varies by gender, age, accent, and for users with speech impediments. Testing must be conducted specifically against the demographic characteristics of the intended caller population, not just against general population benchmarks. For enterprises with elderly customer bases, non-native speaker populations, or customers with speech-affecting medical conditions, this calibration work is essential before production deployment.
Quiet room dependency: Liveness detection performs optimally in relatively controlled audio environments. Call center implementations where customers call from noisy locations — construction sites, public transport, open offices — will experience elevated false rejection rates. This is a physical constraint of acoustic analysis, not a Pindrop-specific limitation. The architecture response is to configure fallback authentication flows that don’t strand legitimate customers when environmental noise causes liveness score degradation.
Healthcare AI Agents: HIPAA-Compliant Voice Authentication (Why Anonybit Beats Pindrop for Medical Use Cases)

For healthcare AI agent deployments, the storage architecture is the decisive factor and it’s why Anonybit’s decentralized model has a clear advantage over centralized voice biometric platforms in HIPAA-regulated environments.
HIPAA’s Minimum Necessary Standard requires that covered entities limit access to protected health information (PHI) to the minimum necessary for a given function. Anonybit’s architecture satisfies this at the biometric level — no node has access to more than a shard of the biometric template, and the authentication process doesn’t require exposing the complete template to any single party. That’s a natural fit for a regulatory framework built around data minimization.
The Business Associate Agreement (BAA) requirement is where centralized biometric platforms face friction in healthcare. Any vendor that handles PHI on behalf of a covered entity must sign a BAA, and that agreement must include appropriate security safeguards, breach notification requirements, and audit provisions. Platforms that process audio containing incidentally disclosed health information (a common occurrence in patient-facing contact centers) need a BAA that covers that incidental PHI exposure.
Anonybit offers BAA execution for healthcare deployments. The decentralized architecture means that even if a node is compromised, the compromised data is a biometric shard not PHI in any usable form. This simplifies the BAA scope considerably compared to a centralized biometric platform where a breach could expose complete voice templates associated with patient records.
Integration with Epic and Cerner is handled through FHIR-compatible API layers rather than direct platform integration. Your patient identity in Epic maps to a DID in Anonybit when a patient calls, voice authentication resolves the DID, which maps to the Epic patient ID, and the agent retrieves the authorized subset of records using the patient’s identity token. The patient biometric never touches Epic; the identity resolution happens in Anonybit’s layer and passes only the patient identifier to the clinical system.
Patient enrollment rates are a real operational challenge. Biometric enrollment for a patient population requires capturing a biometric sample from each patient before the system can authenticate them. Healthcare organizations with large existing patient bases need a phased enrollment strategy new patients enroll at first interaction, existing patients are invited to enroll through patient portal communications with clear consent language.
Financial Services: Can You Use Pindrop for AI Trading Agents Without Violating SEC Audit Requirements?
For AI trading agents, the regulatory question isn’t primarily about biometrics it’s about the audit trail. SEC Rule 17a-4 requires electronic records related to financial transactions to be preserved in a non-rewriteable, non-erasable format for defined retention periods. FINRA has issued guidance indicating that AI systems involved in trade decision-making are subject to supervision requirements — including documentation of how the AI was authorized to act and what controls were in place.
Pindrop’s voice authentication, in a trading context, establishes that a specific verified human authorized the initiation of an agent-driven trading strategy. That authorization event “at 09:42 EST, [verified identity] authorized [agent ID] to execute [strategy] within [parameters]” needs to be logged in a format that satisfies Rule 17a-4. Pindrop itself produces this log. The question is whether your integration pipes that log into your WORM (Write Once, Read Many) compliance archive.
Anonybit’s identity token, in the same scenario, provides the cryptographic binding between the human authorization and the agent’s actions throughout the trading session. The token carries the scope of authorization which instruments, which position sizes, which risk parameters and every agent action can be validated against that scope in the audit log.
The liability question for AI agent errors in trading is unsettled law. Current SEC guidance doesn’t assign liability to AI systems it assigns it to the human or firm that authorized the system and failed to supervise it adequately. Identity binding and scoped authorization are your evidence that supervision was in place that the agent was operating within explicitly defined, human-authorized parameters and that every action was logged against a verified identity.
SOX Section 404 internal control requirements apply to publicly traded companies’ financial reporting processes. If AI agents are involved in any process that feeds into financial reporting expense categorization, accounts payable, journal entries those agents’ authorization architecture is in scope for your SOX 404 assessment.
Government & Defense: Why NIST 800-63-3 Compliance Forces You to Rethink AI Agent Identity
NIST 800-63-3, the Digital Identity Guidelines, establishes three assurance levels for identity and authentication in federal systems. For AI agents operating in government and defense contexts, compliance requires explicit mapping of the agent’s authorization to these assurance levels.
Identity Assurance Level 3 (IAL3) requires in-person or supervised remote identity proofing with biometric binding. For AI agents operating on behalf of government personnel accessing sensitive systems, the human behind the agent must have their identity verified at IAL3. If the original identity proofing was only at IAL1 or IAL2, the authorization chain doesn’t support IAL3-required access — regardless of how sophisticated the agent’s runtime authentication is.
Authenticator Assurance Level 3 (AAL3) requires a hardware-based authenticator and biometric as part of authentication. Voice biometric liveness detection combined with Anonybit’s MPC-backed template management achieves AAL3 specifically, the combination of “something you are” (biometric) with cryptographic assurance of template integrity (MPC) meets the AAL3 requirement for multi-factor authentication.
FedRAMP Authorization is required for any cloud service used by federal agencies to store, process, or transmit federal data. Before deploying either Pindrop or Anonybit in a federal environment, verify their FedRAMP authorization status and the authorization boundary specifically, whether the biometric data processed or stored is within the FedRAMP boundary or whether additional controls are needed for data that crosses that boundary.
FICAM (Federal Identity, Credential, and Access Management) architecture provides the framework for how federal agencies manage identity for both humans and non-human entities (including AI agents). The FICAM enterprise identity risk management framework explicitly addresses non-person entities (NPEs) — which is the category that AI agents fall into. FICAM guidance for NPEs requires that the NPE’s identity be bound to and authorized by a human identity owner, with audit trails connecting NPE actions to human accountability. This maps directly to Anonybit’s identity-bound agent architecture.
Why Users Hate Voice Authentication (And How to Fix the “Please Repeat Yourself” Problem)
The user experience problem with voice authentication isn’t technical it’s emotional. Being asked to repeat a phrase multiple times while trying to get help with an urgent problem creates frustration that customers associate with the brand, not with the security system.
Voice deepfake detection technology analyzes subtle acoustic and behavioral traits during authentication, and in well-implemented systems, the authentication analysis happens while the customer is having a natural conversation, not while they’re reading a scripted passphrase into the phone. Passive voice biometrics, where the voiceprint is captured from conversational speech rather than commanded enrollment phrases significantly reduces this friction.
Passive voice biometrics works by building a voiceprint from the first 10–20 seconds of natural conversational speech. No enrollment phrase. No “please say your account number.” The customer explains why they’re calling, and authentication completes in the background. If the voiceprint doesn’t match or if liveness detection flags an issue, the system steps up to a secondary check but for the majority of legitimate callers, authentication is invisible.
Enrollment abandonment is a real operational problem. Customers who are asked to enroll in voice biometrics at the start of an interaction, before getting help with whatever they called about, frequently abandon the enrollment. Progressive enrollment addresses this by completing enrollment across multiple interactions rather than requiring it all at once. The customer’s first call captures a partial voiceprint. Their second call extends it. By the third or fourth interaction, the voiceprint is complete — without the customer ever feeling like they went through an enrollment process.
False rejection is the single biggest driver of voice authentication abandonment. A customer who calls twice and gets rejected both times stops trusting the system and demands a human agent. The false rejection rate management requires ongoing model calibration against your actual customer population — not vendor-provided benchmarks from different populations.
Cultural differences in biometric acceptance are real and matter for global deployments. Consumer acceptance of voice biometric authentication varies significantly across markets. Customers in markets with high awareness of voice fraud (China, Hong Kong) are often more willing to use multi-factor authentication including biometrics. Markets with lower fraud awareness but higher privacy sensitivity (Germany, Netherlands) require more explanation and explicit consent mechanisms before adoption rates reach sustainable levels.
Silent Authentication: Can AI Agents Verify Identity Without Users Knowing? The Privacy Paradox
Passive authentication where identity verification happens in the background without an explicit challenge is technically possible and operationally desirable. It’s also legally complex and ethically contested.
From a user experience standpoint, silent authentication is ideal. The agent verifies that it’s talking to the right person without interrupting the conversation, slowing down the interaction, or creating friction. The customer gets faster, smoother service. The enterprise gets verification without abandonment.
From a legal standpoint, the picture is more complicated. GDPR requires that individuals be informed when their biometric data is being processed. Collecting a voiceprint in the background of a customer service call, without explicitly disclosing that biometric processing is occurring, may violate transparency requirements under Article 13 and Article 9. Even if consent to “record this call for quality purposes” was obtained at the start of the interaction, that consent doesn’t automatically extend to biometric template extraction from the recording.
The practical resolution used by compliant enterprises is disclosure without friction. The IVR message at the start of the call includes a brief disclosure: “This call may use voice technology to verify your identity and protect your account.” That’s sufficient disclosure for most jurisdictions. It doesn’t require the customer to actively enroll or accept it informs them that biometric processing is occurring so that their consent can be inferred from their continued participation.
For the EU specifically, inferred consent for biometric data under Article 9 is legally contested. Biometric data is special category data that typically requires explicit rather than inferred consent. The Digital Omnibus proposals from November 2025 proposed a new Article 9 exemption for biometric verification/authentication that would simplify this, but those proposals are not yet law. Until the Omnibus is finalized, EU deployments of passive voice authentication should include an opt-out mechanism and a functional alternative authentication path for customers who decline.
The behavioral biometrics layer adds another dimension. Behavioral biometrics typing patterns, mouse movement, touch screen interaction, speech cadence can be collected entirely passively, with no explicit user action required. This is the most friction-free authentication signal available, and it’s also the one with the most contested consent implications in EU law. Legal review of your specific deployment context is essential before enabling behavioral biometrics in any EU-regulated environment.
Revolutionize AI agents transforming recruitment! Cut hiring costs 40%, find elite talent instantly—scale your team effortlessly!.
API Latency Wars: How to Achieve Sub-100ms Voice Verification for Real-Time AI Agents
Sub-100ms end-to-end voice verification is achievable for real-time agents, but it requires architectural choices that most out-of-the-box implementations don’t make by default.
The latency budget for a voice authentication API call breaks down as follows:
- Audio capture and encoding: 10–20ms
- Network transit to API endpoint: 5–50ms (dependent on regional proximity)
- Audio analysis at the API layer: 20–80ms (dependent on model complexity and hardware)
- Response transit back: 5–50ms
- Score processing and decision: 5–15ms
Total: 45–215ms, with the primary variable being network transit and analysis time.
To get consistently under 100ms:
Edge deployment: Deploy Pindrop’s API integration at the nearest AWS, Azure, or GCP region to your contact center infrastructure. For call centers in Northern Virginia, use US-East-1. For London, use EU-West-2. Each additional network hop adds 20–30ms that you can’t recover from.
Streaming audio analysis: Don’t buffer the complete audio utterance before sending to the API. Stream audio in real time and start liveness analysis on the first 500ms of speech. Pindrop’s streaming API mode initiates analysis immediately, producing a preliminary score before the utterance completes. The final score is confirmed at utterance completion, but an early risk signal is available within the first second.
WebSocket vs. REST: For real-time voice streams, WebSocket connections to the Pindrop API maintain an open connection and stream audio continuously, eliminating the HTTP connection overhead (typically 30–50ms) that a REST request per audio chunk would add. WebSocket implementations achieve meaningfully lower latency for ongoing session monitoring.
Async verification for low-risk actions: Not every agent decision needs synchronous authentication. For agent actions below a risk threshold reading account information, answering general questions authentication can be verified asynchronously against the session’s cached liveness score. Only high-risk actions (transactions, account modifications) require synchronous re-verification. This approach reduces the latency impact of authentication to only the moments that actually matter.
Dive into affordable AI agent frameworks for startups! Transparent pricing unlocks enterprise power—launch without breaking bank!
The “Template Aging” Problem: Why Voice Biometrics Degrade Over Time
Voice biometrics enrolled today may not reliably authenticate the same person in five years. Voice changes with age, health, emotional state, and medication. This is a real operational problem that gets almost no attention in vendor documentation.
The acoustic properties of a person’s voice shift gradually over years due to physiological changes in the vocal tract, respiratory capacity, and neural control of speech. A voiceprint enrolled at age 35 will show measurable divergence from the same person’s voice at age 45. How much divergence before authentication fails? That threshold is configurable set it too tight and you get false rejections for aging users, set it too loose and you reduce security against impersonation.
Acute changes are more dramatic. A user with laryngitis, a head cold, or certain medications may fail voice authentication completely despite being the legitimate account owner. Seasonal allergies alone can cause acoustic shifts that degrade voiceprint matching accuracy.
Adaptive template updating addresses this by incrementally updating the enrolled template based on successful authentication events. Each time a user authenticates successfully, the system uses that new voice sample to slightly update the stored template toward the current voice characteristics. Over time, the template tracks the user’s evolving voice.
The security risk in adaptive updating is that it can be abused. If an attacker makes a series of calls that partially match the current template and each partial match updates the template slightly toward the attacker’s voice, the template can be gradually shifted toward the attacker’s voice over many interactions. Implementing update gates requiring a minimum authentication confidence score before a template update is accepted, and limiting the rate of template change per time period mitigates this risk.
Anonybit’s decentralized storage supports template updates through a re-enrollment protocol that requires the original authentication assurance to be re-established before the new template is accepted. This prevents the gradual drift attack while allowing legitimate template evolution.
The CISO’s Dilemma: Budgeting for AI Agent Security When Board Members Don’t Understand the Risk
The conversation most CISOs struggle with isn’t technical it’s economic. “How much are we spending on securing AI agents that haven’t had an incident yet?” is harder to answer than “how much did last year’s breach cost us?”
The FAIR (Factor Analysis of Information Risk) framework provides a structure for translating AI agent security risk into financial terms that a board can engage with.
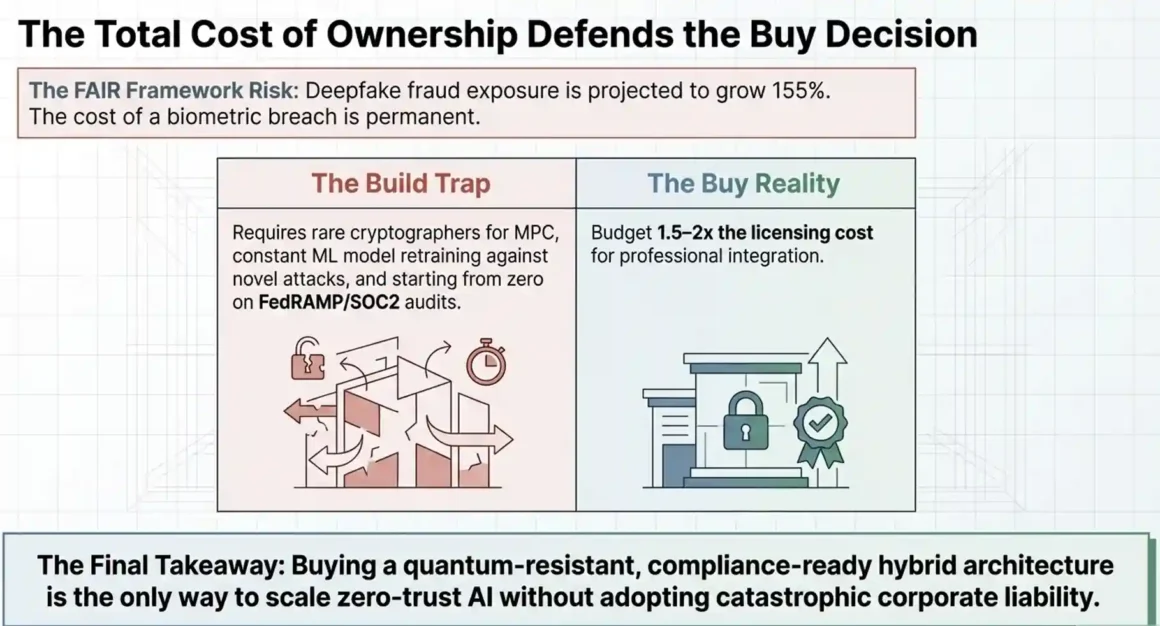
The analysis starts with threat frequency. Pindrop’s 2025 report projects that contact centers could face $44.5 billion in total fraud exposure in 2025, with deepfaked calls projected to increase 155% and deepfake-related fraud expected to grow 162%. Your enterprise’s share of that exposure is proportional to your call volume and transaction value. A contact center processing 10,000 calls per day with average transaction values of $500 has a materially different exposure calculation than a contact center handling account inquiries with no direct transaction capability.
The “probable loss magnitude” for a biometric breach differs from a password breach in a critical way: you cannot change a biometric. A compromised password is solved by issuing a new password. A compromised voiceprint or facial biometric is a permanent credential exposure. Every future use of that biometric by the legitimate user is now suspect. The remediation cost re-enrollment in a new biometric modality, legacy account migration, fraud monitoring extends for years after the initial breach event.
For board presentations: frame the investment as fraud prevention with a calculable ROI, not as security overhead with an indefinite cost. “Implementing voice liveness detection at our contact centers costs X annually. Our current fraud exposure is Y annually. Detection technology with a 99% effectiveness rate reduces that exposure by approximately Y×0.99. The net cost is X − (Y×0.99).” If that math is negative, you’re not just buying security you’re buying profit.
Cyber insurance implications are increasingly concrete. Several insurers now offer premium reductions for enterprises that can demonstrate specific AI agent security controls including biometric liveness detection and identity binding. The premium reduction may not cover the entire solution cost, but it changes the budget conversation from “security spending” to “insurance optimization.”
Master LangChain vs Agent Zero framework battle! Ditch heavy chains for sleek power—build unstoppable agents instantly!
Building vs. Buying AI Agent Identity: The 2025 TCO Analysis
The build-versus-buy decision for AI agent identity infrastructure is usually made on the basis of upfront cost. It shouldn’t be. The decision should be made on five-year total cost of ownership, and when that analysis is done honestly, buying almost always wins.
Build cost factors (frequently underestimated):
- MPC cryptographic implementation requires deep expertise that most enterprise security teams don’t have. Hiring or contracting cryptographers to implement SSS correctly, harden it against known attack vectors, and maintain it as threat models evolve costs more than a year of Anonybit licensing for most organizations.
- Biometric model training and maintenance requires ongoing datasets, GPU compute, and ML engineering. Liveness detection models degrade against novel attack vectors and must be retrained regularly. Pindrop maintains their models against a live threat intelligence feed a build scenario means you maintain your own.
- Security audits of custom cryptographic implementations are expensive and take time. Penetration testers specializing in biometric systems and MPC implementations are rare and charge premium rates.
- Compliance attestation for a custom-built biometric platform requires independent third-party audit. Established vendors like Pindrop and Anonybit maintain existing SOC 2 Type II certifications and FedRAMP authorizations that transfer to your deployment. Building from scratch means earning those certifications from zero.
Buy cost factors (the real ones, not the marketing ones):
- Implementation costs are real and often underquoted. A Pindrop integration to a non-standard telephony environment or a Anonybit deployment to a complex multi-cloud enterprise architecture requires professional services investment. Budget 1.5–2x the licensing cost for implementation in the first year.
- Customization limitations exist. Both Pindrop and Anonybit support configuration within their platforms, but highly specific workflow requirements unusual agent orchestration patterns, proprietary identity management systems may require custom development on top of the purchased platform. Scope this before signing.
- Vendor dependency is real. If Pindrop or Anonybit is acquired, pivots their product roadmap, or faces financial difficulty, your security infrastructure is affected. Data portability clauses ensuring you can export your enrolled biometric templates and identity records on reasonable notice must be in your contract.
Five-year TCO models consistently favor buying for organizations below approximately 500 developer headcount. Above that threshold, the economics become more complex, but the operational risk argument (the difficulty of maintaining cryptographic security infrastructure at the required standard) still usually favors purchasing from specialists.
Discover Agent Zero vs LangGraph showdown! Simple autonomy beats graph complexity—deploy faster, scale smarter today!
When Voice Authentication Fails: 3 Catastrophic AI Agent Breaches and What They Teach Us
These are documented incidents, not hypotheticals. The patterns they reveal should directly inform your architecture decisions.
Incident 1 — Hong Kong HSBC deepfake ring (April 2025)
Hong Kong police dismantled a deepfake scam ring in April 2025 that used AI-generated video and cloned voice attacks to open accounts at HSBC, causing losses exceeding HK$1.5 billion (approximately US$193.2 million).
Root cause: The attack combined synthetic voice with synthetic video in a coordinated multi-modal assault. Single-modality liveness detection (voice only or video only) was bypassed because each modality was tested separately. The attack succeeded specifically because the verification pipeline didn’t cross-validate voice liveness against video liveness in a unified risk score.
Lesson: Multi-modal deepfake attacks require multi-modal liveness detection with cross-modal validation. A high-confidence voice liveness score combined with a low-confidence video liveness score should produce a combined low-confidence result — not two independent “pass” decisions.
Incident 2 — Indonesian financial institution KYC bypass (2025)
An Indonesian financial institution suffered 1,100 deepfake attacks bypassing their loan application biometric verification service, with investigators estimating a financial impact of $138.5 million and attackers obtaining victim IDs through malware, social media, and the dark web.
Root cause: The attack was a digital injection attack — synthetic biometric data was injected directly into the data stream between the user’s device and the verification server, bypassing the capture device entirely. Standard liveness detection operates on the assumption that it’s analyzing data captured from a live user. Injection attacks present synthetic data as if it were live capture.
Lesson: Network-level attestation of data origin is required. The verification system needs to confirm not just that the biometric sample looks live, but that it originated from an authenticated capture device that hasn’t been compromised. Hardware attestation (Trusted Platform Module, secure enclave) at the capture device level is the defense.
Explore Agent Zero vs AutoGen multi-agent comparison! Discover lightweight speed crushing complex teams—choose winning frameworks for your AI projects now!
Incident 3 — North Korean threat actor KnowBe4 hiring fraud (2024)
Cybersecurity company KnowBe4 discovered in July 2024 that a remote software engineer they had hired was a North Korean threat actor using a stolen U.S. identity and an AI-enhanced photograph, having passed multiple video interviews.
Root cause: The identity verification process during hiring checked documents, not biometrics. The AI-enhanced photo passed visual inspection. No liveness detection was applied to the video interview footage.
Lesson: AI agents in HR and hiring workflows face the same identity verification gap as contact center agents. Liveness detection isn’t just for customer authentication — it’s for any high-stakes interaction where the identity of the person behind the screen determines the trust level of the session.
Frequently Asked Questions
Why are AI agent deployments failing due to identity gaps?
AI agents inherit the authorization level of the service account or API key they operate under — not the verified identity of the human they’re acting for. When that service account is compromised, or when the agent is manipulated through a deepfake voice attack, it acts with full authorization on behalf of an unverified or malicious identity. The fix is binding agents to verified human identities using biometric authentication and cryptographic token scoping.
What is Pindrop’s deepfake detection rate?
Pindrop’s liveness detection technology demonstrates a 99% detection rate with a false positive rate under 1% in controlled testing. Real-world performance varies based on audio environment, caller demographics, and attack sophistication. Independent testing should be conducted against your specific call population before production deployment.
What is Anonybit’s “Genie” and how does it store biometrics?
Anonybit’s platform fragments biometric templates using Multi-Party Computation (MPC) and Shamir’s Secret Sharing (SSS), distributing shards across geographically separated nodes. No single node holds a complete, usable biometric. Reconstruction requires threshold consensus from multiple nodes, providing quantum-resistant security and GDPR compliance by design.
Does combining Pindrop and Anonybit satisfy GDPR Article 9?
The combination supports GDPR Article 9 compliance when implemented correctly. Anonybit’s decentralized architecture satisfies data minimization and privacy-by-design requirements. Explicit consent or another Article 9(2) condition must still be established for biometric processing in EU jurisdictions. The EU Digital Omnibus (November 2025) proposes a new verification/authentication exemption under Article 9 that would simplify compliance further but is not yet law.
What is an identity-bound AI agent?
An identity-bound AI agent is one that operates under a cryptographically scoped authorization token tied to a verified human identity not a generic service account. The agent can only perform actions within the token’s defined scope, all actions are logged against the human identity, and the authorization expires automatically. Anonybit launched the first production implementation of identity-bound agents in May 2025 through its partnership with SmartUp.
How do you handle AI agent identity when an employee leaves?
Automated offboarding workflows should revoke all Anonybit identity tokens bound to the departing employee’s DID immediately upon their removal from the enterprise identity provider. Agents carrying those tokens are suspended pending re-authorization under a new human identity owner. All agent actions from the 30 days prior to offboarding should be logged and retained for audit purposes.









